Extract text from PDF document in Make
Extracts text from a PDF document to Text or HTML format with the help of Make. Check out our blog for a detailed example of how to extract text from PDF in Make with Plumsail Documents. Or continue reading this section to learn the key configuration details for the extract text action in Make.
Parameters
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
Text or raw HTML from the result file. |
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head><title></title>
<meta http-equiv="Content-Type" content="text/html; charset="UTF-8">
</head>
<body>
<div style="page-break-before:always; page-break-after:always">
<div>
<p>
<b>3</b>
</p>
</div>
</div>
<div style="page-break-before:always; page-break-after:always">
<div>
<p>
<b>4</b>
</p>
</div>
</div>
<div style="page-break-before:always; page-break-after:always">
<div>
<p>
<b>5</b>
</p>
</div>
</div>
<div style="page-break-before:always; page-break-after:always">
<div>
<p>
<b>6</b>
</p>
</div>
</div>
<div style="page-break-before:always; page-break-after:always">
<div>
<p>
<b>7</b>
</p>
</div>
</div>
</div></div>
</body>
</html>
|
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
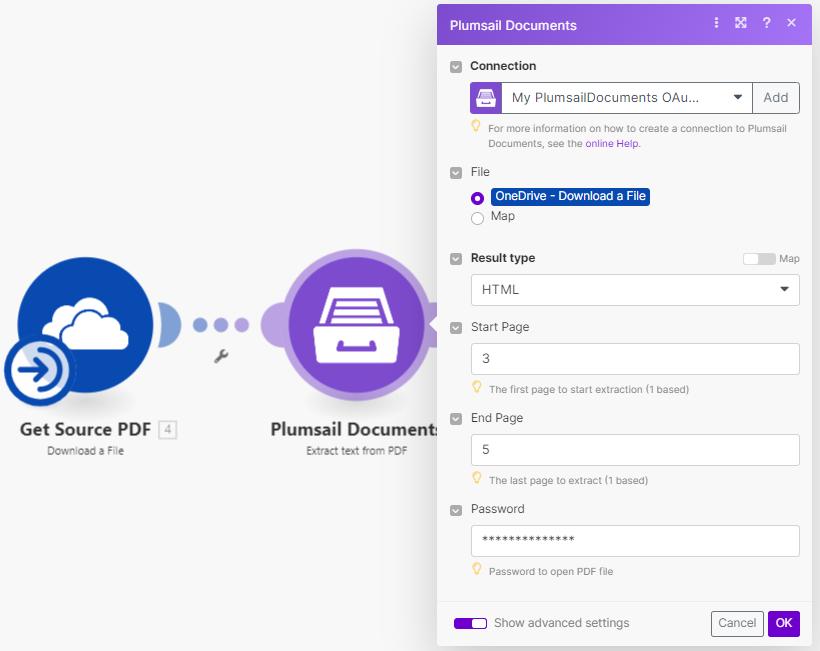
Connection |
To allow your scenarios to get information from and send it to Plumsail Documents, you need to create a connection. |
For more information on how to create a connection to Plumsail Documents, see the online Help. |
File |
The content of PDF document. |
You may get the content of the source PDF from the OneDrive app or from some other app. |
Result Type |
Text or HTML. |
HTML |
Start Page |
Index of the first page to start extraction (indexes start from 1). |
3 |
End Page |
Index of the last page to extract (inclusive). By default, we use the last page of the source document. |
7 |
Password |
The password to decrypt the source document if it was encrypted earlier. |
PAs$word |
Example
Download a source PDF file and use the output in the Extract text from PDF action.