Power Automate actions and triggers
This connector helps you to automatically generate and convert documents with the help of Power Automate (Microsoft Flow). Before starting, ensure that you added Plumsail Documents connector to Power Automate (Microsoft Flow).
Triggers
The connector has only one trigger. Find it below.
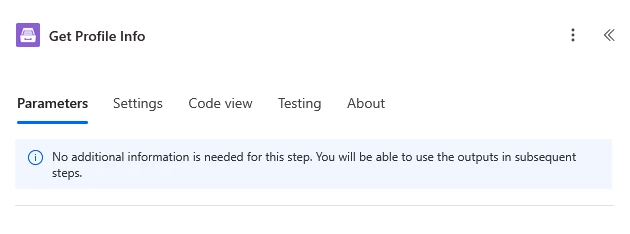
Process finished
The Power Automate trigger starts when a process of document generation is finished.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
|
An output filename specified in the template settings. |
{
"fileName": "Contract with Contoso LLC"
}
|
|
A URL of the blob file with the content of the document generated by the process. |
{
"fileUrl": "https://actions.blob.core.windows.net/.../..."
}
|
|
An object with the source data submitted to the process. |
{
"data": {
"Client": "Contoso LLC",
"Email": "contact@contoso.com",
"@number": 6,
"@date": "2024-06-04T20:43:37.6697922"
}
}
|
|
An object containing data from the deliveries in the process. Note: for now, it works only with a DocuSign delivery. |
{
"deliveriesData": {
"docuSign": [
{
"bulkEnvelopeStatus": null,
"envelopeId": "a1e01b1b-4aa4-4244-ad5d-549b47bcc7z2",
"errorDetails": null,
"recipientSigningUri": null,
"recipientSigningUriError": null,
"status": "sent",
"statusDateTime": "2024-06-04T10:43:42.8430000Z",
"uri": "/envelopes/a1e01b1b-4aa4-4244-ad5d-549b47bcc7z2"
}
]
}
}
|
|
An object containing values of system tokens |
{
"predefinedTokens": {
"@number": 35,
"@date": "2024-06-04T16:31:55.1000608"
}
}
|
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Process name |
Select the required process in a drop-down list. |
Create contracts
|
Example
Actions
Find all available actions below.
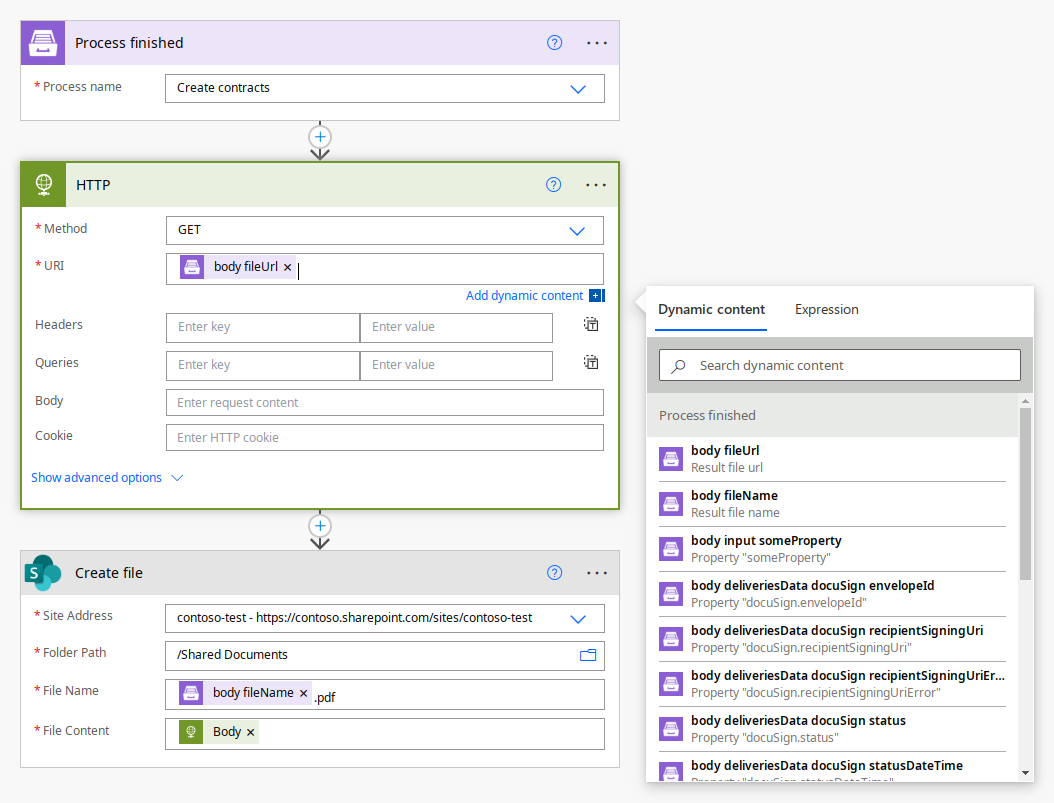
Start document generation process
Starts a process of document generation. Processes are an easy way to automate the creation of documents from templates. You just configure template, test it and specify how to deliver results (email, OneDrive, etc.).
This action automatically adds inputs to the Power Automate interface for entering values based on your template tokens from the process. It may not support deeply nested tokens, and if the Power Automate interface lacks certain inputs, it indicates that the action doesn’t support this kind of nested token structure. In this case, switch to the Start document generation process with JSON action.
Check out the article describing how to use this action.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result file |
The content of the result file generated by a process. |
It is the content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Process name |
Select the name of your process from the list of available processes. |
Create employee card |
Properties values or JSON content |
Data to bind to the template. You can get this data from some other Power Automate (Microsoft Flow) connector. For example you can query SharePoint list or some other system. |
You can either enter property values into the automatically generated fields or switch to JSON mode. This is the JSON data example: [
{
"FirstName": "David",
"LastName": "Navarro",
"Email": "d.navarro@contoso.com",
"Photo": "https://picture-public-url"
}
]
|
Example
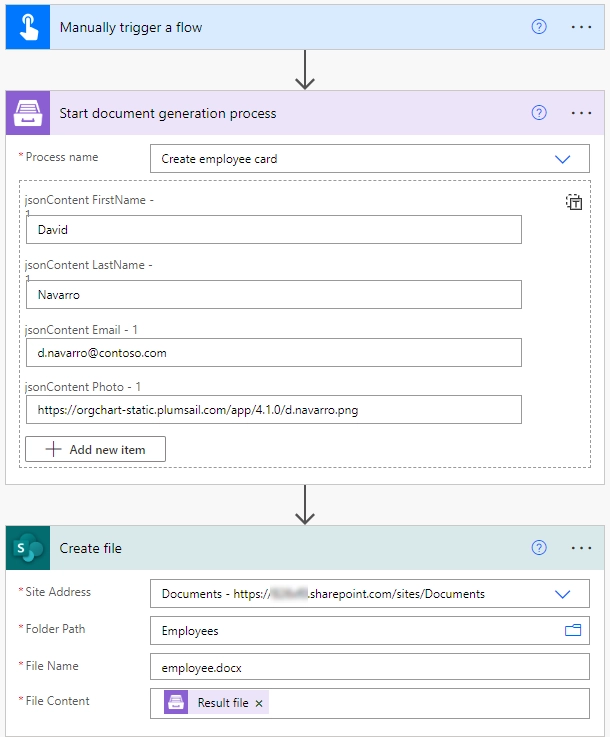
You can also switch to the JSON mode and enter a JSON.
Start document generation process with JSON
The action does the same as Start document generation process but it only works with JSON data.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result file |
The content of the result file generated by a process. |
It is the content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Process name |
Select the name of your process from the list of available processes. |
Create invoice |
Template data |
Data to bind to the template in JSON format. You can get this data from some other Power Automate (Microsoft Flow) connector. For example you can query SharePoint list or some other system. |
JSON data for generating an invoice: {
"companyAddress": "3 Main St.New York NY 97203 USA",
"companyEmail": "sales@sample.com",
"companyPhone": "202-555-0131",
"invoiceNumber": "432",
"total": "18872.94",
"items": [
{
"name": "Monitor",
"quantity": "10",
"cost": "990"
},
{
"name": "Stepler",
"quantity": "1000",
"cost": "12440"
}
]
}
|
Example
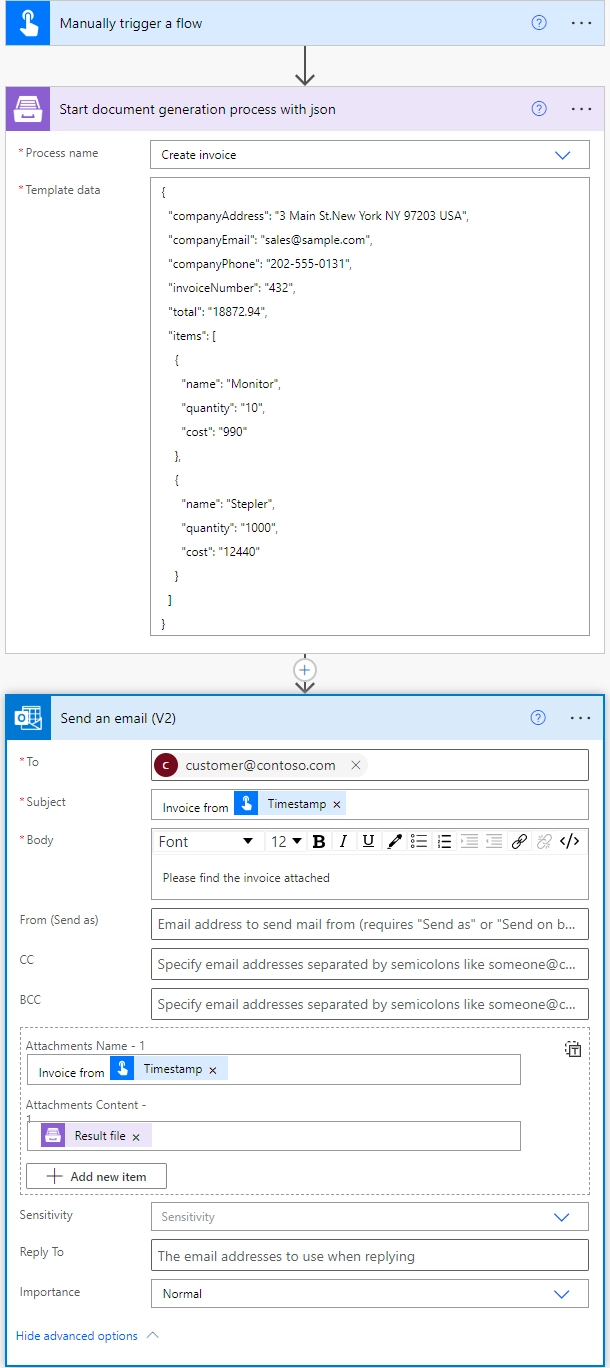
Create document from DOCX template
Creates Word DOCX document from template. Review Word DOCX templates section for more information about template syntax.
We have an article describing how to work with this action in case of managing documents.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result .docx or .pdf file. |
It is the content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Template file |
The raw content of the source .docx template file. You can extract file content from other connectors like:
|
Review Word DOCX templates section for more information about template syntax. Example of simple table template: 
|
Document output type |
You can select the output type of the resulting file: DOCX or PDF. |
DOCX or PDF output |
Template data |
Data to bind to the template in JSON format. You can get this data from some other Power Automate (Microsoft Flow) connector. For example you can query SharePoint list or some other system. |
[
{
"firstName": "Efren",
"lastName": "Gaskill",
"email": "egaskill0@opensource.org",
"payments": [
{
"date": "3/10/2025",
"amount": "$8.91"
},
{
"date": "4/2/2026",
"amount": "$0.56"
}
]
}
]
|
Template engine |
There are two options available: Modern and Classic. We recommend using the Modern engine, as it’s more powerfull and up-to-date. Review Modern vs. Classic DOCX engine article to learn more about differences between template engines. |
Modern |
Locale |
An optional parameter that allow to specify the desired regional culture format. You can pick the value from predefined list. If you don’t specify value, default value will be “en-US” (english, USA). All allowable regional culture formats you can find here . |
en-US |
Time zone |
An optional parameter that allows specifying the desired timezone. |
UTC |
Example
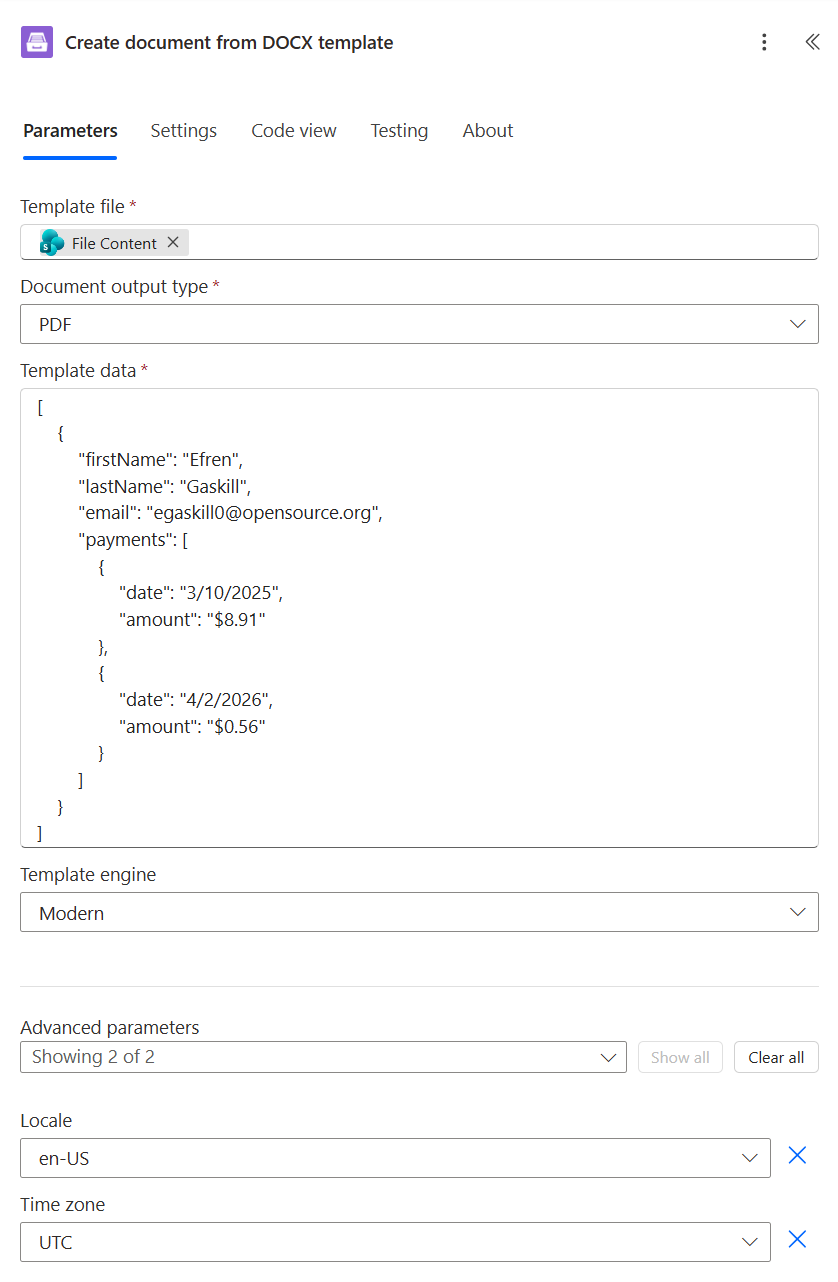
Create document from PPTX template
Creates PPTX presentation from template. Review PowerPoint PPTX templates section for more information about template syntax.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result .pptx or .pdf file. |
It is the content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Template file |
The raw content of the source .pptx template file. You can extract file content from other connectors like:
|
Review PowerPoint DOCX templates section for more information about template syntax. Example of simple slide template: 
|
Template data |
Data to bind to the template in JSON format. You can get this data from some other Power Automate (Microsoft Flow) connector. For example you can query SharePoint list or some other system. |
[
{
"CompanyName": "Contoso",
"CompanyEmail": "support@contoso.com",
"Products": [
{
"Name": "Documents",
"Price": "starting from $29.99/month"
},
{
"Name": "Actions",
"Price": "starting from $29.99/month"
}
]
}
]
|
Document output type |
You can select the output type of the resulting file: PPTX or PDF. |
PPTX or PDF output. |
Locale |
An optional parameter that allow to specify the desired regional culture format. You can pick the value from predefined list. If you don’t specify value, default value will be “en-US” (english, USA). All allowable regional culture formats you can find here |
|
Time zone |
An optional parameter that allows specifying the desired timezone. |
UTC |
Example
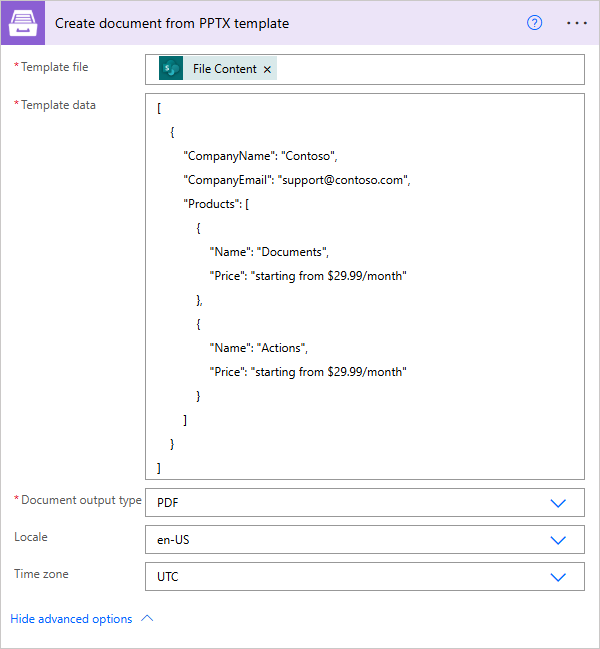
Create document from XLSX template
Creates Word XLSX document from template. Review Excel XLSX templates section for more information about template syntax.
Also there is an article describing how to work with this action in case of managing documents.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result .xlsx or .pdf file. |
It is the content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Template file |
The raw content of the source .xlsx template file. You can extract file content from other connectors like:
|
Review Word XLSX templates section for more information about template syntax. Example of simple table template: 
|
Template data |
Data to bind to the template in JSON format. You can get this data from some other Power Automate (Microsoft Flow) connector. For example you can query SharePoint list or some other system. |
[
{
"firstName": "Efren",
"lastName": "Gaskill",
"email": "egaskill0@opensource.org",
"payments": [
{
"date": "3/10/2018",
"amount": "$8.91"
},
{
"date": "1/7/2018",
"amount": "$0.56"
}
]
}
]
|
Document output type |
You can select the output type of the resulting file: XLSX or PDF. |
XLSX or PDF output. |
Locale |
An optional parameter that allow to specify the desired regional culture format. You can pick the value from predefined list. If you don’t specify value, default value will be “en-US” (english, USA). All allowable regional culture formats you can find here |
|
Time zone |
An optional parameter that allows specifying the desired timezone. |
UTC |
Example
Create HTML from template
Generates raw HTML from a raw HTML template with the help of Power Automate (Microsoft Flow). You can find more examples in this article.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result HTML |
Raw HTML result created from a source HTML template. |
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>HTML from template</title>
</head>
<body>
<ul>
<li>David Navarro </li>
<li>Jessica Adams</li>
<li>Derek Clark</li>
</ul>
</body>
</html>
|
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Source HTML |
HTML content of a source template. You can specify raw HTML here or extract file content from other connectors like:
|
You can find description of template syntax in this article. <!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>HTML from template</title>
</head>
<body>
<ul>
{{#each data}}
<li>{{name}}</li>
{{/each}}
</ul>
</body>
</html>
|
Template data |
Data to bind to the template in JSON format. You can get this data from some other Power Automate (Microsoft Flow) connector. For example you can query SharePoint list or some other system. |
{
"data": [
{
"name": "David Navarro "
},
{
"name": "Jessica Adams"
},
{
"name": "Derek Clark"
}
]
}
|
Locale |
An optional parameter that allow to specify the desired regional culture format. You can pick the value from predefined list. If you don’t specify value, default value will be “en-US” (english, USA). All allowable regional culture formats you can find here |
|
Time zone |
An optional parameter that allows specifying the desired timezone. |
UTC |
Example

Fill Merge Fields in DOCX document
Creates .docx document by filling merge fields in a .docx document with the help of Power Automate (Microsoft Flow). You can find more examples in this article.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result .docx file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
DOCX document content |
The raw content of the source .docx file with merge fields. You can extract file content from other connectors like:
|
You can find instructions about creation of a document with merge fields in this article. Use this link to download the sample document. |
Template data |
Data in JSON format that will be used to fill merge fields in the source document. You can get this data from some other Power Automate (Microsoft Flow) connector. For example you can query SharePoint list or some other system. |
{
"EmployerFullName": "David Navarro",
"EmployeeFullName": "Anil Mittal",
"CompanyName": "Contoso LLC",
"Position": "Marketing manager",
"SalaryAmount": 5000,
"ListOfBenefits": "list of any benefits that come with employment",
"BonusesPolicyDescription": "annual evaluation",
"EffectiveDate": "10/27/2024",
"TerminationDate": "10/27/2025",
"State": "New York"
}
|
Example
Convert to PDF
The action accepts different types of files and converts them to PDF.
Supported File Extensions
Type |
Extension |
|---|---|
Text |
.doc, .docx, .docm, .dot, .dotx, .dotm, .rtf, .odt, .ott, .text, .txt |
Table |
.xls, .xlsx, .csv, .ods, .ots, .xlsb, .xltx, .tsv, .xlsm |
Presentation |
.ppt, .pptx, .pps, .ppsx, .odp, .potx, .pptm, .ppsm, .potm, .otp |
Hypertext |
.htm, .html, .mhtml, .mht |
.eml, .msg |
|
Image |
.bmp, .jpg, .jpeg, .png, .tiff, .tif, .jfif, .heic, .webp, .avif, .gif, .psd |
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result file |
The content of the result PDF file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
The raw content of the source file. You can extract file content from other connectors like:
|
It is a Base64 encoded content of the source file. |
Example

Convert DOCX to PDF
Converts .docx document to PDF document with the help of Power Automate (Microsoft Flow). You can find more examples in this article.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result PDF file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
The raw content of the source .docx file. You can extract file content from other connectors like:
|
It is content of the source file. |
Example

Convert XLSX to PDF
Converts .xlsx document to PDF document with the help of Power Automate (Microsoft Flow). You can find more examples in this article.
Note
This action supports formulas compatible with Excel 2019.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result PDF file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
The raw content of the source .xlsx file. You can extract file content from other connectors like:
|
It is content of the source file. |
Example

Convert DOC to DOCX
Converts .doc document to .docx document with the help of Power Automate (Microsoft Flow).
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result DOCX file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
The raw content of the source .doc file. You can extract file content from other connectors like:
|
It is content of the source file. |
Example

Convert XLS to XLSX
Converts .xls document to .xlsx document with the help of Power Automate (Microsoft Flow). Find the description of how to bulk convert .xls to .xlsx in this article.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result XLSX file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
The raw content of the source .xls file. You can extract file content from other connectors like:
|
It is content of the source file. |
Example

Convert PPT to PPTX
Converts .ppt document to .pptx document with the help of Power Automate (Microsoft Flow).
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result PPTX file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
The raw content of the source .ppt file. You can extract file content from other connectors like:
|
It is content of the source file. |
Example

Convert PPTX to PDF
Converts .pptx document to PDF document with the help of Power Automate (Microsoft Flow).
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result PDF file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
The raw content of the source .pptx file. You can extract file content from other connectors like:
|
It is content of the source file. |
Example

Convert HTML to PDF
Converts HTML document to PDF document with the help of Power Automate (Microsoft Flow). You can find more examples in this article.
Note
There could be an issue converting certain symbols such as £. Add the following line in the HTML head element
<meta http-equiv=”Content-Type” content=”text/html; charset=UTF-8”>
You can find more information about using custom fonts with Convert HTML to PDF action here.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result PDF file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Source HTML |
HTML content of a source file. You can specify raw HTML here or extract file content from other connectors like:
|
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>HTML to PDF example
<style>
div {
border: 1px solid lightgray;
padding: 5px;
float: left;
}
</style>
</head>
<body>
<div>
Text in box1
</div>
<div>
Text in box2
</div>
</body>
</html>
|
Engine |
Defines what engine is used when converting the source HTML to PDF. |
|
Paper Size |
Paper size for output PDF file. |
|
Orientation |
Page orientation for output PDF file. |
|
Margins |
The page margins in millimeters. The syntax is the same as in CSS. |
This will set top margin as 25mm, right margin as 50mm, bottom margin as 75mm, left margin ias 100mm. |
Header HTML (Modern engine) |
HTML markup that should be added as a Header. If you want to use styles, add CSS directly to the Header HTML code. |
<!DOCTYPE html>
<html>
<head>
<title>Test</title>
</head>
<body id="header" style="margin-bottom: 130px;">
<div style="font-size:10px !important; color:#808080; padding-left:10px">
This is header
<br/>
Title: <span class="title"></span>
</div>
</body>
</html>
|
Footer HTML (Modern engine) |
HTML markup that should be added as a Footer. If you want to use styles, add CSS directly to the Footer HTML code. Also, with the Modern Engine you can use pageNumber and totalPages as a class of an element to automatically add the values. PageNumber: <span class="pageNumber"></span>
<br/>
TotalPage: <span class="totalPages"></span>
|
<!DOCTYPE html>
<html>
<head>
<title>Test</title>
</head>
<body id="footer">
<div style="font-size:10px !important; color:#808080; padding-left:10px">
Footer Text.
<br/>
PageNumber: <span class="pageNumber"></span>
<br/>
TotalPage: <span class="totalPages"></span>
<br/>
<p>email: <a>contact@plumsail.com</a>.</p>
</div>
</body>
</html>
|
Header HTML (Classic engine) |
HTML markup that should be added as a Header. |
<!DOCTYPE html>
<html>
<head>
<title></title>
</head>
<body>
This is header
</body>
</html>
|
Footer HTML (Classic engine) |
HTML markup that should be added as a Footer. |
<!DOCTYPE html>
<html>
<head>
<title></title>
</head>
<body>
This is footer
</body>
</html>
|
Example
Convert HTML to DOCX
Converts HTML to a DOCX document
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result DOCX file. |
It is a |
Input Parameters
Note
The source HTML should be provided only through one of these fields:
File Content
HTML Data
HTML URL
Parameter |
Description |
Example |
|---|---|---|
File Content |
File content of a source HTML file. You can extract it from other Power Automate connectors. |
It is a |
HTML Data |
Raw HTML provided as plain text. |
<!DOCTYPE html>
<html>
<body>
<h1>My Heading</h1>
<p>My paragraph.</p>
</body>
</html>
|
HTML URL |
URL to a publicly available web page. |
https://contoso.com/info
|
Paper size |
Paper size in the result DOCX document. |
Letter
|
Orientation |
Page orientation in the result DOCX document. |
Portrait
|
Decode HTML |
Defines whether to decode HTML. |
No
|
Margins |
Margins of the result DOCX file in |
25 50 75 100
|
Example
Convert JSON to Excel
Converts JSON object to an Excel worksheet.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result file |
The content of the result Excel file. |
It is a |
Input Parameters
Note
The source JSON should be provided only through one of these fields:
JSON File Content
JSON Data
Parameter |
Description |
Example |
|---|---|---|
JSON File Content |
File content of a source JSON file. You can pass it as dynamic output from other connectors. |
It is a |
JSON Data |
Raw JSON content of a source object. You can enter it as plain text here or pass the dynamic output from other connectors. |
{
"data": {
"rows": [{
"column1": "value11",
"column2": 12
},
{
"column1": "value21",
"column2": 22
}
]
}
}
|
Locale |
Defines formatting of some data types according to the specified locale, for example of a date. |
en-US
|
Path To JSON Array |
Defines path to the JSON property containing an array of objects that should be processed as rows in the result Excel file. |
data.rows
|
Mapping |
Defines a data type of the specified property and an accordant column name in the result Excel file. You can either map each property separately or provide an entire array. A sample of the latter is in the next column. |
[
{
"jsonProperty": "column1",
"xlsxColumnType": "Text",
"xlsxColumnName": "Column 1"
},
{
"jsonProperty": "column2",
"xlsxColumnType": "Integer",
"xlsxColumnName": "Column 2"
}
]
|
Example
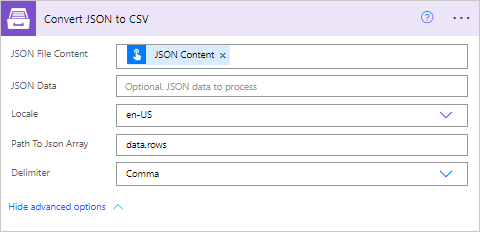
Convert JSON to CSV
Converts JSON object to a CSV table.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result file |
The content of the result CSV table. |
column1,column2
value11,12
value11,22
|
Input Parameters
Note
The source JSON should be provided only through one of these fields:
JSON File Content
JSON Data
Parameter |
Description |
Example |
|---|---|---|
JSON File Content |
File content of a source JSON file. You can pass it as dynamic output from other connectors. |
It is a |
JSON Data |
Raw JSON content of a source object. You can enter it as plain text here or pass the dynamic output from other connectors. |
{
"data": {
"rows": [{
"column1": "value11",
"column2": 12
},
{
"column1": "value21",
"column2": 22
}
]
}
}
|
Locale |
Defines formatting of some data types according to the specified locale, for example of a date. |
en-US
|
Path To JSON Array |
Defines path to the JSON property containing an array of objects that should be processed as rows in the result CSV table. |
data.rows
|
Delimiter |
Defines a delimiter in the result CSV table. |
Comma
|
Example
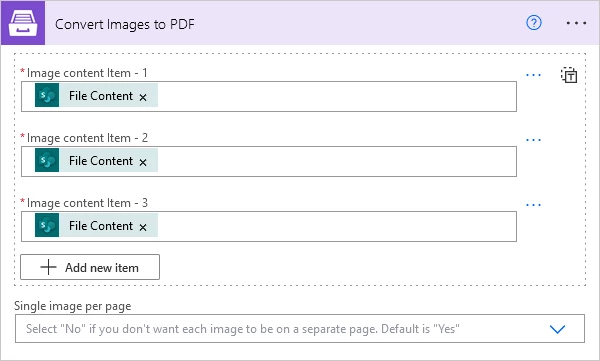
Convert Images to PDF
Converts one or more images to a PDF document with the help of Power Automate (Microsoft Flow). Review How to convert an array of images to PDF in Power Automate article for more information.
Supported File Extensions
.bmp, .jpg, .jpeg, .png, .tiff, .tif, .jfif, .heic, .webp, .avif, .gif, .psd
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result PDF file. |
It is the Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Image files content |
The array of raw content of image files. |
You can get the content of image files from the “Get file content” action from the “SharePoint” connector or from a different connector. |
Single image per page |
Store each image on a separate page in the result PDF document. Default value is “Yes”. |
No |
Example
You can add individual files:
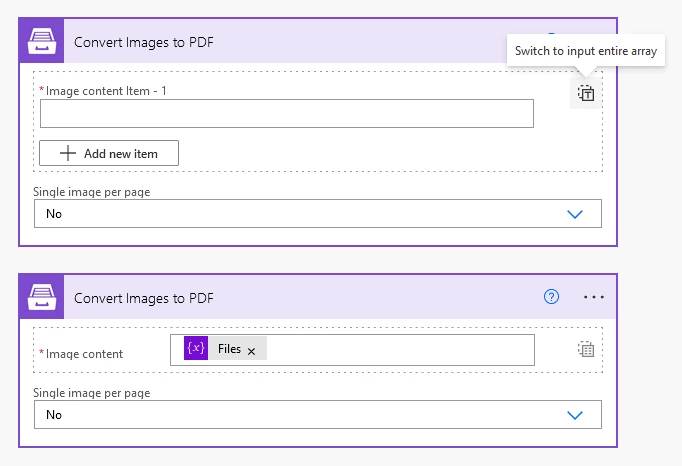
You can also input an array of files. Click an icon on the right to switch to the view where you can input an entire array and select the array from the dynamic content in Power Automate:
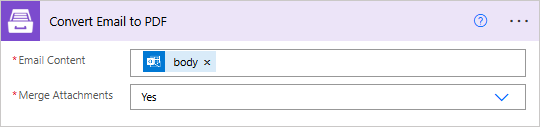
Convert Email to PDF
Converts email content (.eml or .msg) to a PDF document with the help of Power Automate (Microsoft Flow).
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result file |
The content of the result PDF file. |
It is a |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Email content |
The raw content of the source .eml or .msg file. |
You can get the content of email files from an “Export email” action of an “Office 365 Outlook” connector or a different one. |
Merge attachments |
If set to “Yes”, it includes image and PDF attachments into the output PDF. |
No |
Example
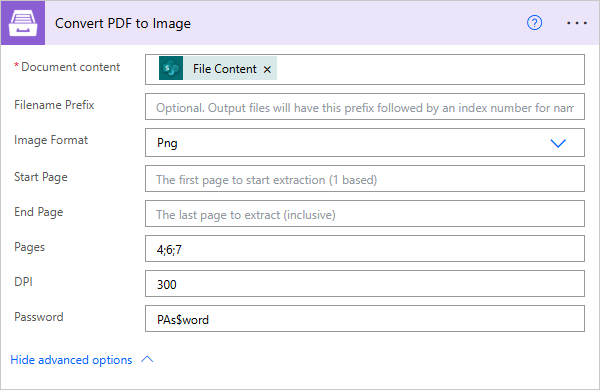
Convert PDF to Image
Converts PDF document to image (jpeg, png, gif, bmp) with the help of Power Automate (Microsoft Flow).
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result Files Contents |
The array of raw content of result image files. |
It is an array of Base64 encoded contents of result image files. You can iterate through them and save somewhere. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document Content |
Raw content of PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. |
Filename Prefix |
Optional: Output files will have this prefix followed by an index number as their name. |
Contract |
Image Format |
The format of the result image. |
|
Start Page |
Index of the first page to start extraction (indexes start from 1). |
3 |
End Page |
Index of the last page to extract (inclusive). By default we will use the last page of the source document. |
7 |
Pages |
Page numbers for extraction separated by ‘;’ (only these pages will be extracted). |
4;6;7 |
DPI |
The resolution of the result image (150 based). |
300 |
Password |
The password to decrypt the source document. If it was encrypted earlier. |
PAs$word |
Example
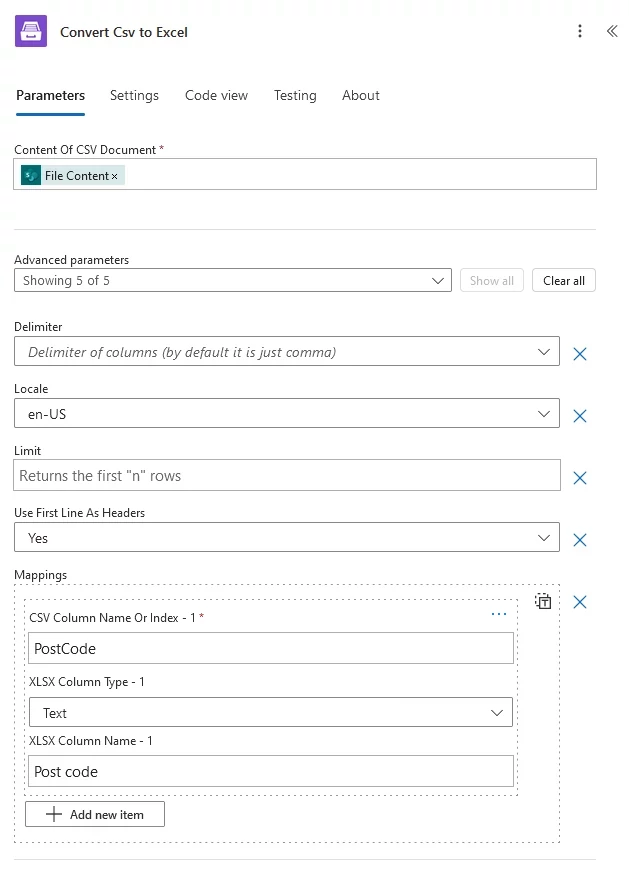
Convert CSV to Excel
Converts a CSV file to Excel in Power Automate (Microsoft Flow). Review How to convert CSV files to Excel in Power Automate Flow article for more information.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
Raw content of result file |
It is a Base64 encoded content of result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Content of CSV document |
The raw content of the source CSV file. You can extract file content from other connectors like:
|
It is the content of the source file. |
Delimiter |
Delimiter of columns. By default it’s a comma. |
You can select from the following default values: Comma, Semicolon, Tab, Pipe or specify a custom value. |
Locale |
The locale that will be applied to the document. |
Specify the locale in order to correctly convert currencies, dates and other depending values. |
Limit |
Returns the first “n” rows |
You can limit the number of returned rows from the source document. |
Use first line as headers |
Select ‘Yes’ to read headers from the first line of the source CSV |
If your CSV file has headers as a first line, select ‘Yes’. |
Mappings |
Optional mappings of fields in the source CSV to fields in the resulting XLSX document. Refer to the Mapping Parameters section below for details. |
Refer to the Mapping Parameters section below. |
Mapping Parameters
Optionally, you can add mappings of fields in the source CSV to fields in the resulting XLSX document. This is useful if you want to specify user‑friendly column names or apply preformatting to cell values.
Parameter |
Description |
Example |
|---|---|---|
CSV Column Name Or Index |
Name or index of the CSV column used for remapping. |
Specify the column name (e.g., ‘PostCode’) if the CSV contains headers in the first line. Otherwise, specify the column index (e.g., ‘5’). The index is counted from one. |
XLSX Column Type |
Content type of the column in the resulting XLSX document. Optional. |
One of the available column types, see below for the complete list. |
XLSX Column Name |
Name of the column in the resulting XLSX document. Optional. |
A user-friendly name, e.g. ‘Post code’. |
The following XLSX column types are available:
General - usually displays numeric values as they are written. Rounded values or exponential notation may be displayed for large numbers or in case of short cell width
Integer - displays numeric values as integer numbers
IntegerPercentage - displays numeric values as an integer percentage
Scientific - displays numeric values in exponential notation
ShortDate - displays values as a short date without time
ShortDateTime - displays values as a short date with time
Text - displays values exactly as they have been written. This may be useful, for example, for properly displaying strings that start with 0 (“000123” will not become “123” if Column Type is set to Text)
ThousandInteger - displays numeric values as integer numbers with thousands separators
ThousandTwoDecimal - displays numeric values as decimal numbers with two digits after the decimal point and with thousands separators
TwoDecimal - displays values as decimal numbers with two digits after the decimal point
TwoDecimalPercentage - displays numeric values as a decimal percentage with two digits after the decimal point
Example
Add a watermark to PDF
Add a watermark to PDF action supports a few types of watermarks: HTML, Image, PDF, Text.
You can find the documentation for all watermark types included in “Add a watermark to PDF” action below:
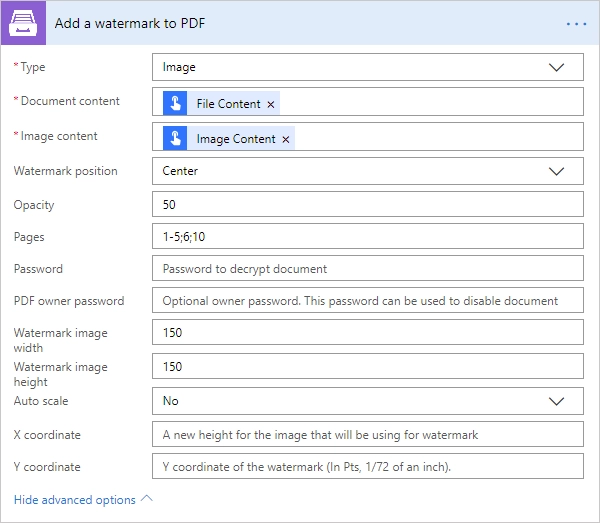
Add image watermark to PDF
Please, see a detailed example.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result PDF file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
Raw content of PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. You may use this link to download a sample 10 pages PDF file. |
Image content |
Raw content of image source. Available extensions: png, tiff, jpg, webp, gif, bmp, svg. |
You may get the content of the source image file by “Get file content” action from “SharePoint” connector or from some other connector. |
Watermark position |
You can select one of the predefined position of watermark on the page. Available preset positions:

|
MiddleRight |
Opacity |
The degree of transparency of the watermark image. This is a percentage value. |
50 |
Pages |
A page range or a list of page numbers separated by ‘;’. |
|
Password |
The password to decrypt the source document. If it was encrypted earlier. |
PAs$word |
PDF owner password |
Enter an optional owner password here. This password can be used to disable document restrictions. |
OwNEr_PAs$word |
Watermark image width |
A new width of the image that will be used for watermark. If set - source image will be resized |
150 |
Watermark image height |
A new height of the image that will be used for watermark. If set - source image will be resized |
100 |
Auto scale |
If true, the image will be scaled as close as possible to the values given in Width and Height while maintaining the original proportions. Otherwise, the image will be converted to the specified Height and Width without preserving the proportions. |
true |
X coordinate |
Absolute X coordinate value. If the predefined positions (see Watermark position) do not suit your needs, you can specify the watermark position using absolute coordinates. The origin is in the bottom-left corner, as shown below: 
If set, the Watermark position parameter is ignored. |
50 |
Y coordinate |
Absolute Y coordinate value. If set, the Watermark position parameter is ignored. |
50 |
Example
Add text watermark to PDF
Please, see a detailed example.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result PDF file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
Raw content of the PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. You may use this link to download a sample 10 pages PDF file. |
Text content |
Text that will be used as watermark |
watermark test |
Angle |
Angle of rotation in degrees. Works only for center and coordinates-based positions. |
45 |
Font |
Selects the typeface for the watermark text. |
Times |
Font Bold |
Enables or disables bold formatting for the watermark text. |
Yes/No |
Font Italic |
Enables or disables italic style for the watermark text. |
Yes/No |
Text Alignment |
Sets the text alignment inside the watermark placeholder. This is different from Watermark position, which moves the whole placeholder on the page. |
Center |
Font size |
The size of the font for the watermark text. |
50 |
Color |
Hex value of html color. You can select the desired color using this tool https://www.w3schools.com/colors/colors_picker.asp |
|
Watermark position |
You can select one of the predefined position of watermark on the page. Available preset positions:
|
MiddleRight |
Opacity |
The degree of transparency of the watermark image. This is a percentage value. |
50 |
Pages |
A page range or a list of page numbers separated by ‘;’. |
|
Password |
The password to decrypt the source document. If it was encrypted earlier. |
PAs$word |
PDF owner password |
Enter an optional owner password here. This password can be used to disable document restrictions. |
OwNEr_PAs$word |
X coordinate |
Absolute X coordinate value. If the predefined positions (see Watermark position) do not suit your needs, you can specify the watermark position using absolute coordinates. The origin is in the bottom-left corner, as shown below:
If set, the Watermark position parameter is ignored |
50 |
Y coordinate |
Absolute Y coordinate value. If set, the Watermark position parameter is ignored |
50 |
Example
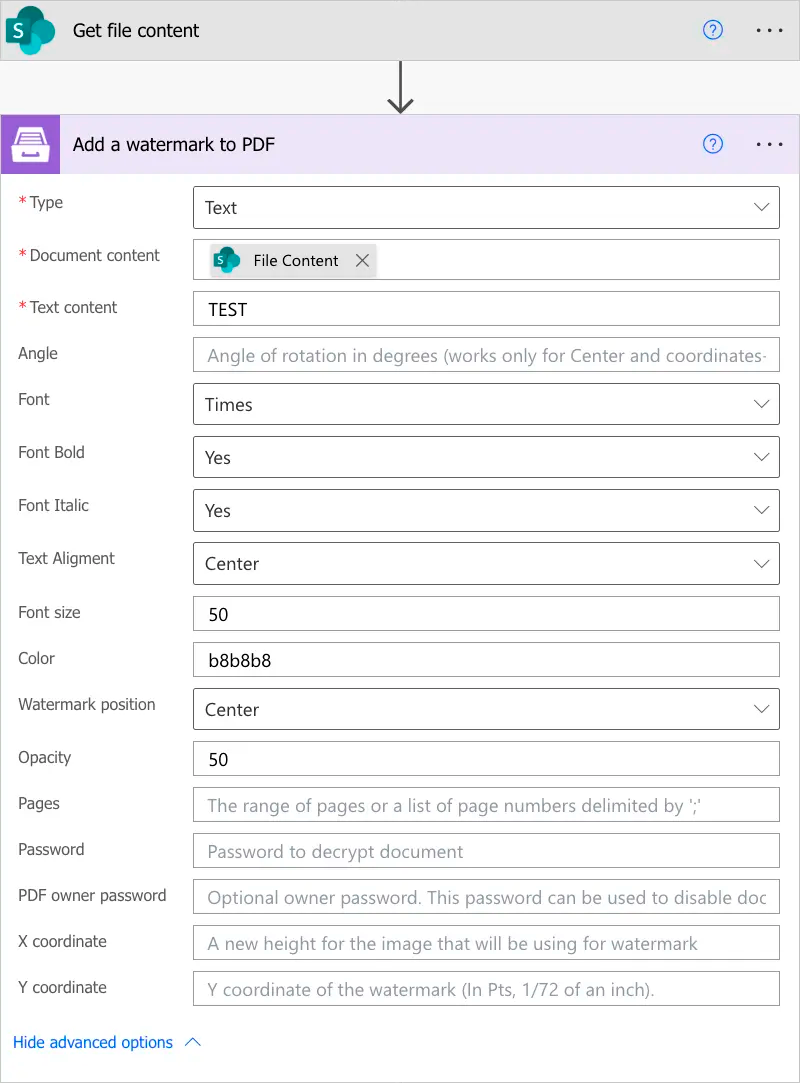
Add pdf watermark to PDF
Please, see a detailed example.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result PDF file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
Raw content of the PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. You may use this link to download a sample 10 pages PDF file. |
PDF watermark document |
Raw content of the PDF file that will be used as a watermark. |
You may use this link to download a sample PDF file for using as PDF watermark. |
Overlay position |
You can select one of the predefined layer for overlay rendering position. Available preset positions:
|
Background |
Pages |
A page range or a list of page numbers separated by ‘;’. |
|
Example
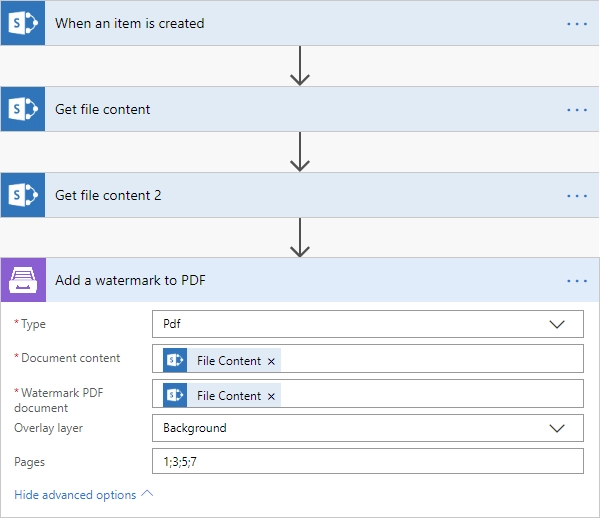
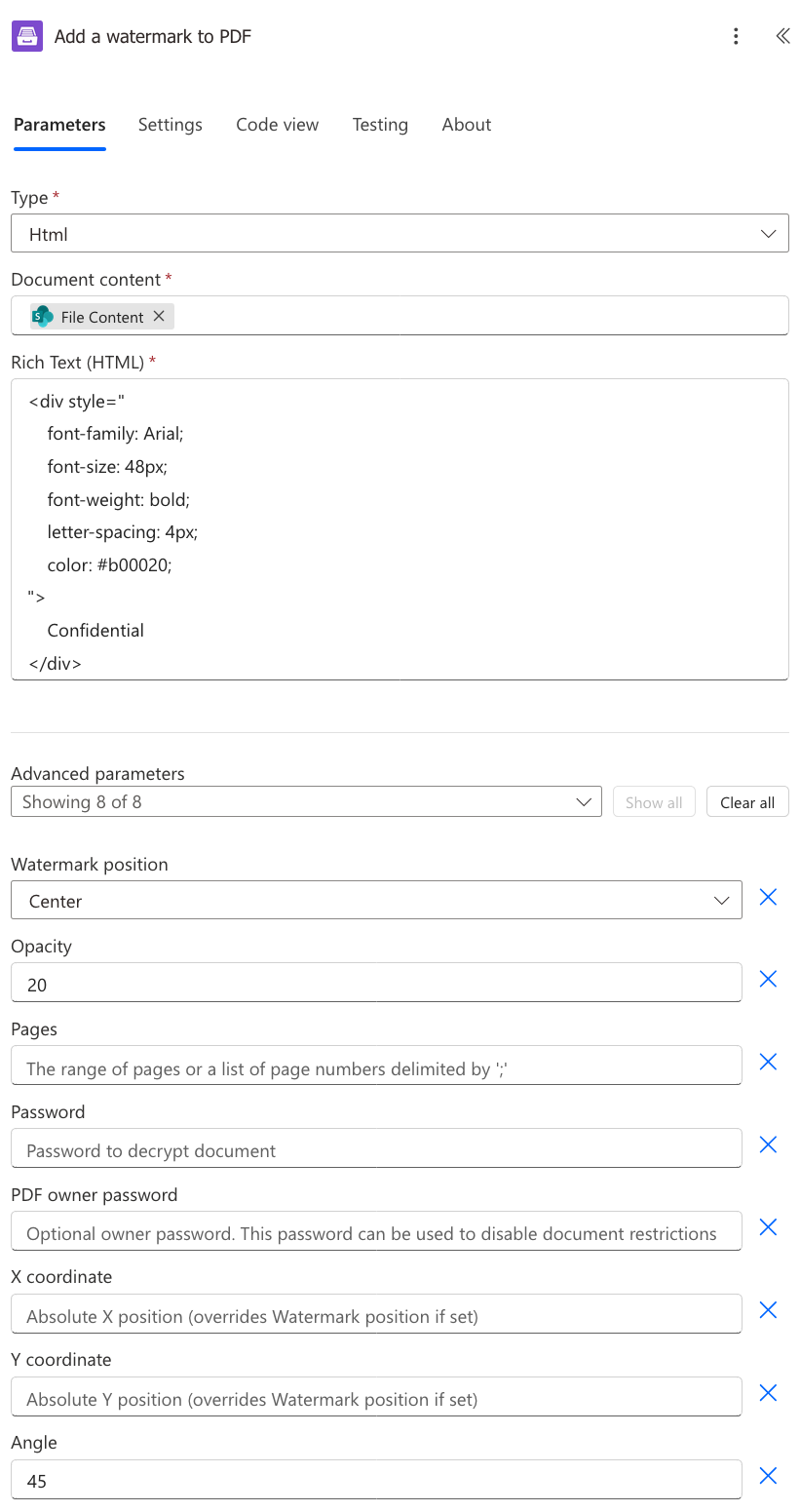
Add Html watermark to PDF
With the HTML watermark, you can create styled watermarks instead of plain text ones. For example, you can include custom typography, colors, opacity, inline images, or dynamic content based on flow data.
See the how-to article for a real use case.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The content of the result PDF file. |
It is a Base64 encoded content of the result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document content |
Raw content of the PDF document. |
You can get the file content using the Get file content action from the SharePoint connector or another connector. You may use this link to download a sample 10 pages PDF file. |
Rich Text (HTML) |
HTML markup used as the watermark content. |
You can get the HTML markup using the Get file content action from the SharePoint connector or another connector. Alternatively, enter the HTML markup directly in the parameter field. For example: <div style="
font-family: Arial;
font-size: 48px;
font-weight: bold;
letter-spacing: 4px;
color: #b00020;
">
Confidential
</div>
|
Watermark position |
You can select one of the predefined position of watermark on the page. Available preset positions:
|
MiddleRight |
Opacity |
The degree of transparency of the watermark image. This is a percentage value. |
50 |
Pages |
A page range or a list of page numbers separated by ‘;’. |
|
Password |
The password to decrypt the source document. If it was encrypted earlier. |
PAs$word |
PDF owner password |
Enter an optional owner password here. This password can be used to disable document restrictions. |
OwNEr_PAs$word |
X coordinate |
Absolute X coordinate value. If the predefined positions (see Watermark position) do not suit your needs, you can specify the watermark position using absolute coordinates. The origin is in the bottom-left corner, as shown below:
If set, the Watermark position parameter is ignored |
50 |
Y coordinate |
Absolute Y coordinate value. If set, the Watermark position parameter is ignored |
50 |
Angle |
Angle of rotation in degrees. Works only for center and coordinates-based positions. |
45 |
Example
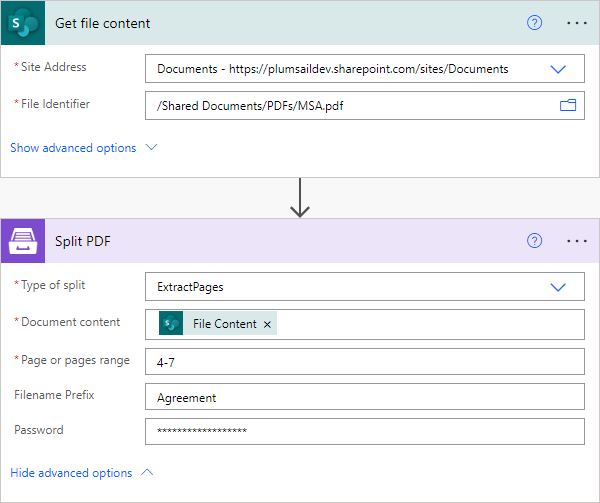
Split PDF
Splits a PDF file with the help of Power Automate (Microsoft Flow). You can find more examples in this article.
There are three types of splits:
Extract pages
Splits a PDF file into chunks as specified in the Page or pages range parameter.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result Files Contents |
The array of raw content of result files. |
It is an array of Binary files. You can iterate through them and save them somewhere. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Type of split |
Select the type of split. |
ExtractPages |
PDF Document Content |
Raw content of PDF document. |
You may get the content of the source PDF by “Get file content” action from “SharePoint” connector or from some other connector. You may use this link to download a sample 10 pages PDF. |
Page or pages range |
Specify a single page to extract, or a range of pages to extract several pages as one file. |
For example, there is a 15 page PDF file. If we specify
|
Filename Prefix |
Optional: Output files will have this prefix followed by an index number as their name. |
Contract |
Password |
Optional: The password required to decrypt the source document if it was encrypted. |
PAs$word |
Example
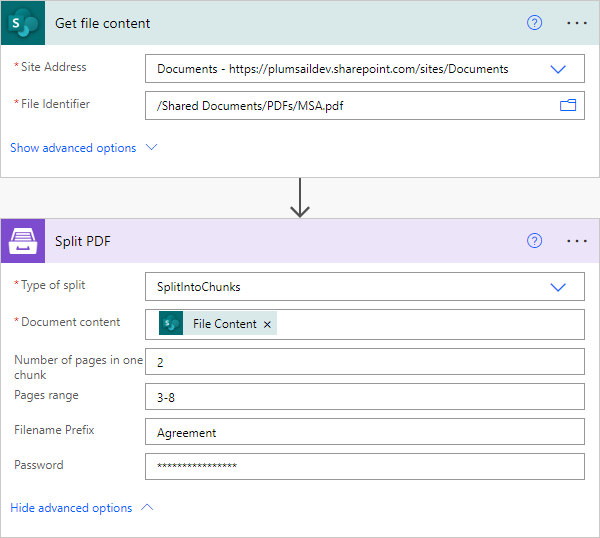
Split into even chunks
Splits a source PDF file into equal chunks as specified by the parameters Number of pages in one chunk and Pages range.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result Files Contents |
The array of raw content of result files. |
It is an array of Binary files. You can iterate through them and save them somewhere. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Type of split |
Select the type of split. |
SplitIntoChunks |
PDF Document Content |
Raw content of PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. You may use this link to download a sample 10 pages PDF. |
Number of pages in one chunk |
Optional. Defines the number of pages in one chunk. |
1 - default number of pages in one chunk. |
Pages range |
Optional. Split the specified pages range. |
For example,
|
Filename Prefix |
Optional: Output files will have this prefix followed by an index number as their name. |
Contract |
Password |
Optional: The password required to decrypt the source document if it was encrypted. |
PAs$word |
Example
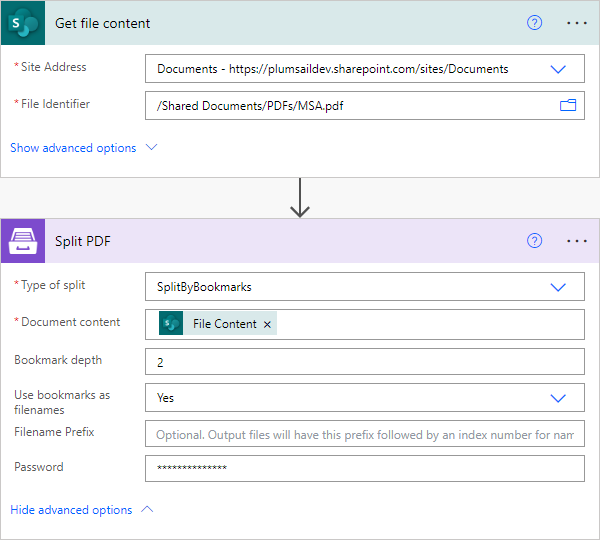
Split by bookmarks
It uses PDF table of contents bookmarks as points to split the document. If multiple bookmarks are on the same page, it creates a duplicate of that page for each bookmark. Essentially, it splits the document into separate files for each chapter from the table of contents.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result Files Contents |
The array of raw content of result files. |
It is an array of Binary files. You can iterate through them and save them somewhere. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Type of split |
Select the type of split |
SplitByBookmarks |
PDF Document Content |
Raw content of PDF document |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. You may use this link to download a sample 10 pages PDF. |
Bookmark depth |
Optional: Depth of bookmark levels to track. By default, it only checks top-level bookmarks, but you can adjust this using the Bookmark depth option. This will allow it to check deeper levels. |
1 - default |
Use bookmarks as filenames |
Optional: Set filenames for each result file based on bookmarks. This option should not be Yes if Filename Prefix is specified. |
Yes |
Filename Prefix |
Optional: Output files will have this prefix followed by an index number as their name. |
Contract |
Password |
Optional: The password required to decrypt the source document if it was encrypted. |
PAs$word |
Example
Merge PDF
Note
The Merge PDF action is deprecated. We recommend using Merge any files to PDF instead for new workflows.
Existing workflows that use Merge PDF will continue to work as usual.
Merge PDF takes an array of PDF documents and merges them into a single file.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
Raw content of the result file. |
It is a |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
PDF Documents Content |
The array of raw content of PDF documents. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. |
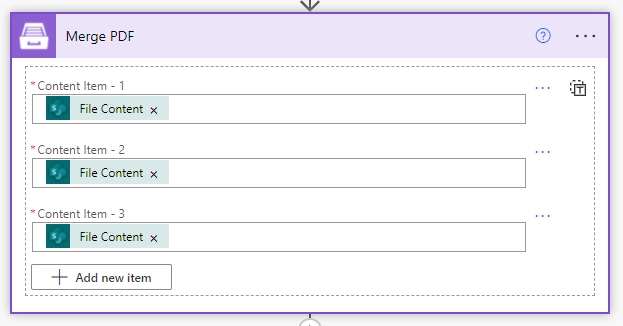
Example
You can add individual files:
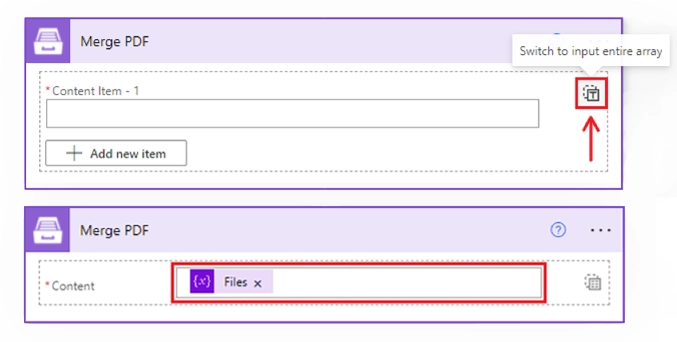
You can also input an array of files. Click an icon on the right to switch to the view where you can input an entire array and select the array from the dynamic content in Power Automate:
Merge DOCX
Merge DOCX takes an array of Docx documents and merges them into a single file.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
Raw content of the result file. |
It is a |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
DOCX Documents Content |
The array of raw content of DOCX documents. |
You may get the content of the source DOCX file by Get file content action from “SharePoint” connector or from some other connector. |
Apply header and footer |
Select whether to include the header and footer in the merged document. |
Yes |
Add page break |
Adds a page break before each merged document. Disable this option to combine DOCX files into one continuous document without page breaks between them. Page breaks already present inside the source files are preserved. Note: If the Merge without break parameter is enabled, the Apply header and footer parameter is always treated as Yes. |
Yes |
Example
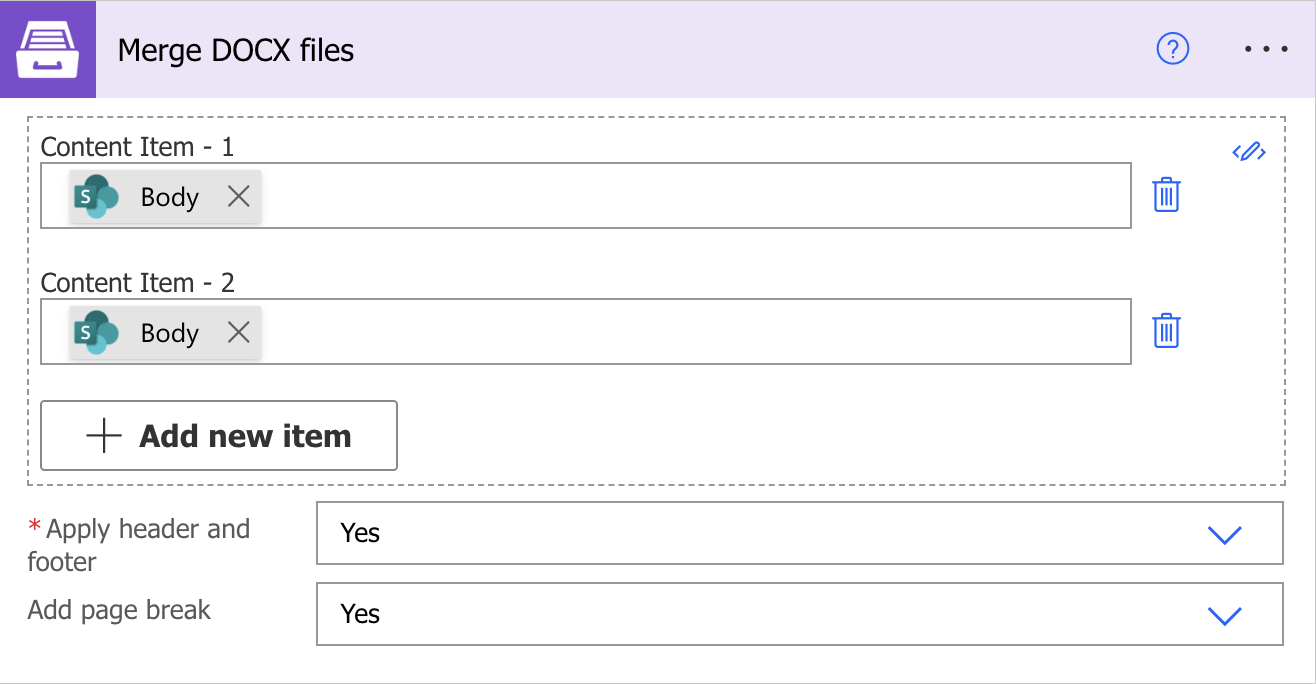
Merge Xlsx
It merges several XLSX workbooks into one.
Note
The action does not support merging charts, they will be omitted in the result document.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result file |
Raw content of the result file. |
It is a |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
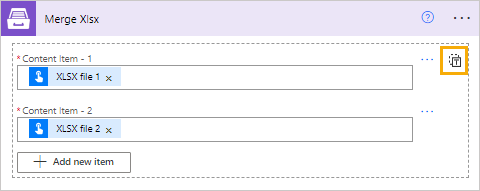
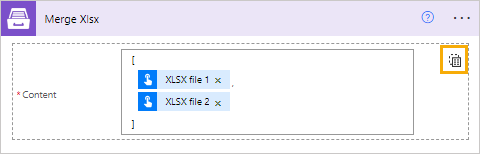
Content items |
The contents of the files to be merged. There are two modes:
|
It is |
Detail input
Array input
Merge any files into PDF
You can merge an array of any files into a single PDF file. Please, see a detailed example.
Supported File Types
Type |
Extension |
|---|---|
Text |
.doc, .docx, .docm, .dot, .dotx, .dotm, .rtf, .odt, .ott, .text, .txt |
Table |
.xls, .xlsx, .csv, .ods, .ots, .xlsb, .xltx, .tsv, .xlsm |
Presentation |
.ppt, .pptx, .pps, .ppsx, .odp, .potx, .pptm, .ppsm, .potm, .otp |
Hypertext |
.htm, .html, .mhtml, .mht |
.eml, .msg |
|
Image |
.bmp, .jpg, .jpeg, .png, .tiff, .tif, .jfif, .heic, .webp, .avif, .gif, .psd |
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
Raw content of the result file. |
It is a |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
The contents of the files to be merged. |
You may get the content of the source file by “Get file content” action from “SharePoint” connector or from some other connector. |
Generate Bookmarks |
Create bookmarks from the original documents that you’re merging. |
For example, if you’re merging several reports, this option will automatically build a navigation tree based on their headings. |
Preserve Bookmarks |
Keeps existing bookmarks from the original documents that you’re merging. |
It’s useful if you’re combining structured documents (like reports or manuals) and you want to keep their original navigation intact. |
Examples
There are two options to provide file contents:
Detail input to provide file contents in separate fields.
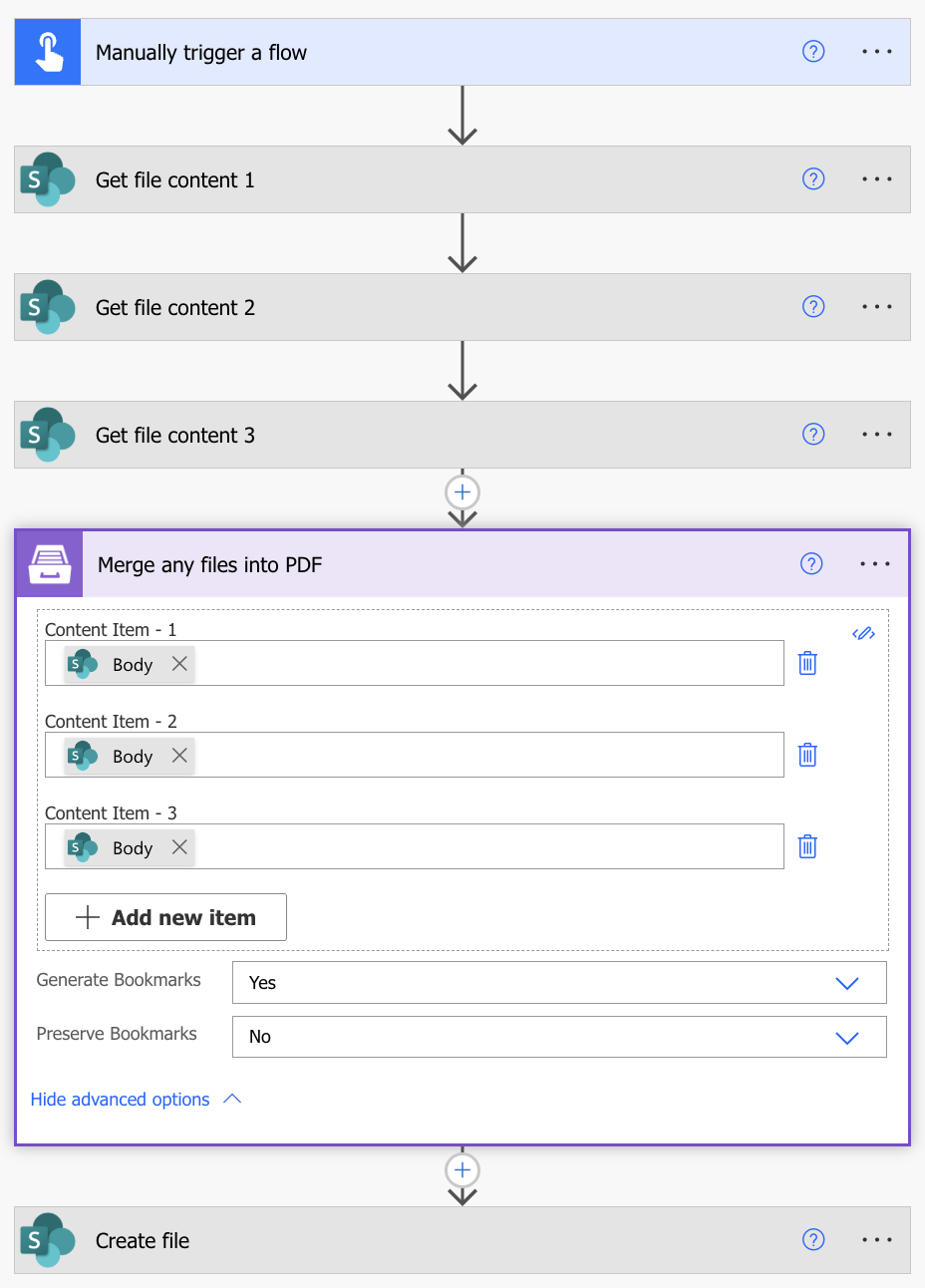
Array input to provide all file contents in a single field as an array. Click an icon on the right to switch to the view where you can input an entire array and select the array from the dynamic content in Power Automate.
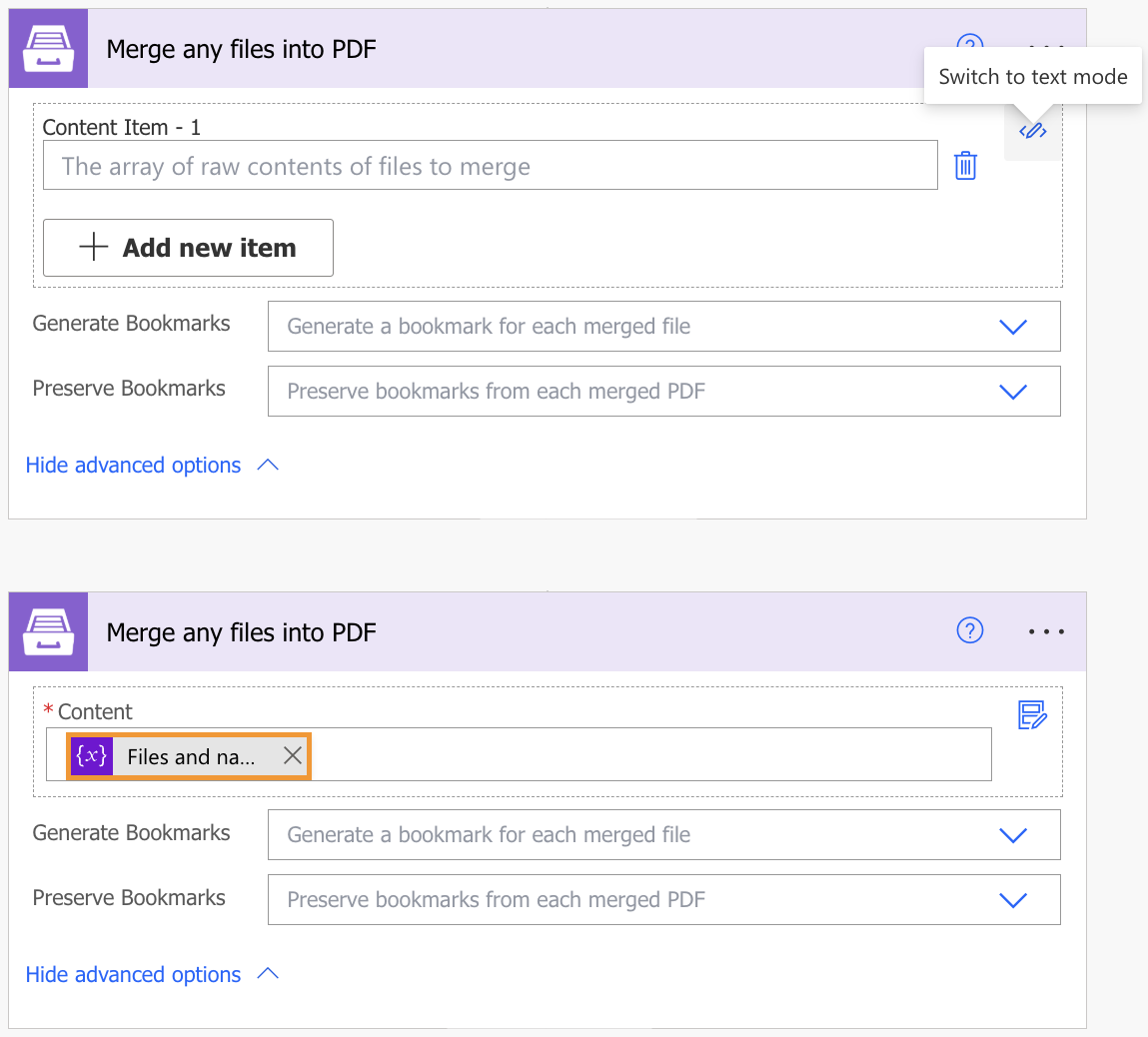
Extract text from PDF document
Extracts text from a PDF document to Raw or HTML format with the help of Power Automate (Microsoft Flow).
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
Text or raw HTML from the result file. |
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head><title></title>
<meta http-equiv="Content-Type" content="text/html; charset="UTF-8">
</head>
<body>
<div style="page-break-before:always; page-break-after:always">
<div>
<p>
<b>3</b>
</p>
</div>
</div>
<div style="page-break-before:always; page-break-after:always">
<div>
<p>
<b>4</b>
</p>
</div>
</div>
<div style="page-break-before:always; page-break-after:always">
<div>
<p>
<b>5</b>
</p>
</div>
</div>
<div style="page-break-before:always; page-break-after:always">
<div>
<p>
<b>6</b>
</p>
</div>
</div>
<div style="page-break-before:always; page-break-after:always">
<div>
<p>
<b>7</b>
</p>
</div>
</div>
</div></div>
</body>
</html>
|
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document Content |
Raw content of PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. |
Result Type |
Raw or HTML. |
HTML |
Start Page |
Index of the first page to start extraction (indexes start from 1). |
3 |
End Page |
Index of the last page to extract (inclusive). By default we will use the last page of the source document. |
7 |
Password |
The password to decrypt the source document if it was encrypted earlier. |
PAs$word |
Example
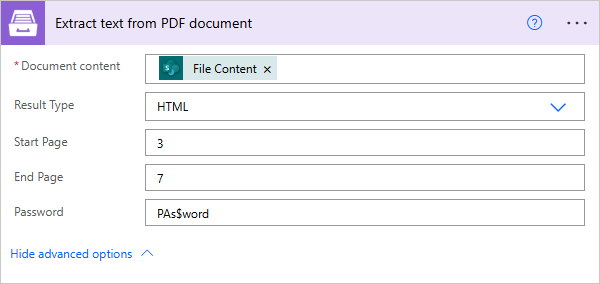
Fill in PDF Form
Fills in PDF form by provided data with the help of Power Automate (Microsoft Flow). Review How to automatically populate fillable PDF based on data from third party system article for more information.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
Raw content of result file. |
It is a Base64 encoded content of result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document Content |
Raw content of PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. |
JSON Data |
The data that will be used to fill in the form. |
{
"FirstName": "David",
"LastName": "Navarro",
"CompanyName": "Contoso LLC",
"Position": "Marketing manager"
}
|
Lock form fields |
Disable fields editing after filling them. |
If you want to lock the fields after filling the PDF form activate the option. |
Password |
The password to decrypt the source document if it was encrypted earlier. |
PAs$word |
Example
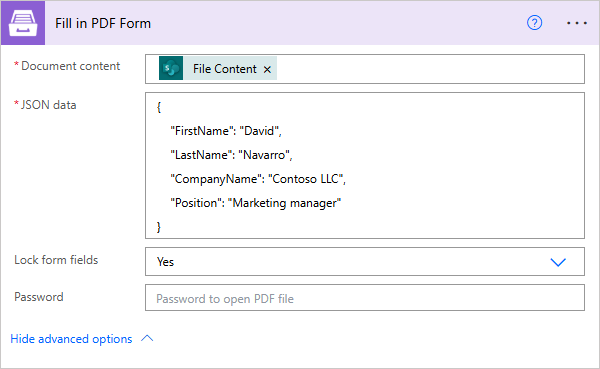
Get Form from PDF
Returns data from fillable PDF as JSON with the help of Power Automate (Microsoft Flow). Review these articles for more information:
How to collect data from fillable PDF and create item in SharePoint
How to extract data from PDF form and create leads in Dynamics CRM
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Form Data |
Data from fillable PDF form as JSON. |
{
"FirstName": "David",
"LastName": "Navarro",
"CompanyName": "Contoso LLC",
"Position": "Marketing manager"
}
|
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document Content |
Raw content of PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. |
Password |
The password to decrypt the source document if it was encrypted earlier. |
PAs$word |
Example
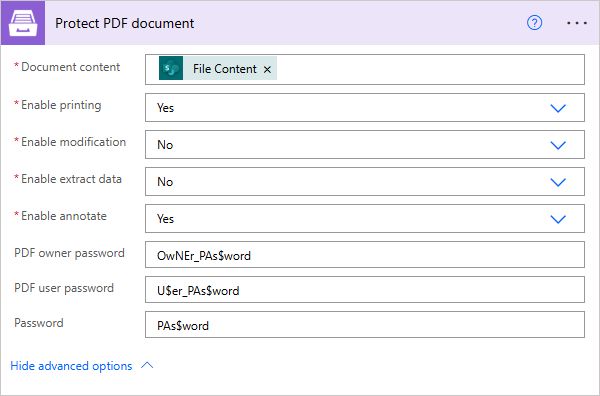
Protect PDF document
Protects PDF by adding passwords, copy-, printing-, and other protections to PDF file with the help of Power Automate (Microsoft Flow).
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
Raw content of result file. |
It is a Base64 encoded content of result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document Content |
Raw content of PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. |
Enable Printing |
Protect the PDF file from being printed out. |
Yes |
Enable Modification |
Protect the PDF file from being edited. |
No |
Enable Extract Data |
Allows extraction of text, images, and other media from the PDF file. |
No |
Enable Annotate |
Allows annotation (e.g. comments, form fill-in, signing) of the PDF file. |
Yes |
PDF Owner Password |
Enter an optional owner password here. This password can be used to disable document restrictions. |
OwNEr_PAs$word |
PDF User Password |
Enter an optional user password here. Each time an user opens the PDF he will be asked for this password. If you do not want a password prompt then leave this field blank. |
U$er_PAs$word |
Password |
The password to decrypt the source document if it was encrypted earlier. |
PAs$word |
Example
Get information about PDF protection
Returns True if the source PDF is protected and False otherwise.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
isPasswordProtected |
True or False. |
You can use If option in the flow to specify further steps depending on the output. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document Content |
Raw content of PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. |

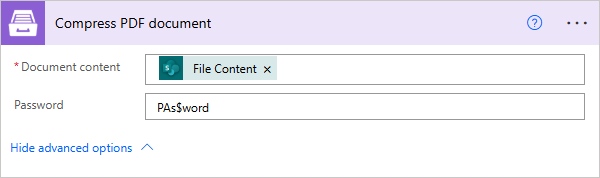
Compress PDF document
Compresses a source PDF document. Please check out the article about using the action.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
Raw content of result file |
It is a Base64 encoded content of result file. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Document Content |
Raw content of PDF document. |
You may get the content of the source PDF file by “Get file content” action from “SharePoint” connector or from some other connector. |
Password |
The password to decrypt the source document if it was encrypted earlier. |
PAs$word |
Parse CSV
Parses a CSV file into an array of objects with properties in Power Automate (Microsoft Flow). Review How to read a CSV file in Power Automate (Microsoft Flow) and bulk generate documents article for more information.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
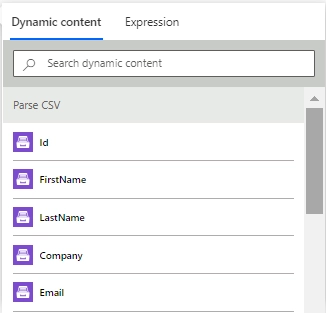
Items |
The collection of objects. Each object represents a CSV row and has properties corresponding to the CSV headers. |
Each CSV header is represented by an output parameter. You can refer to a single item selecting it in MS Flow.
|
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
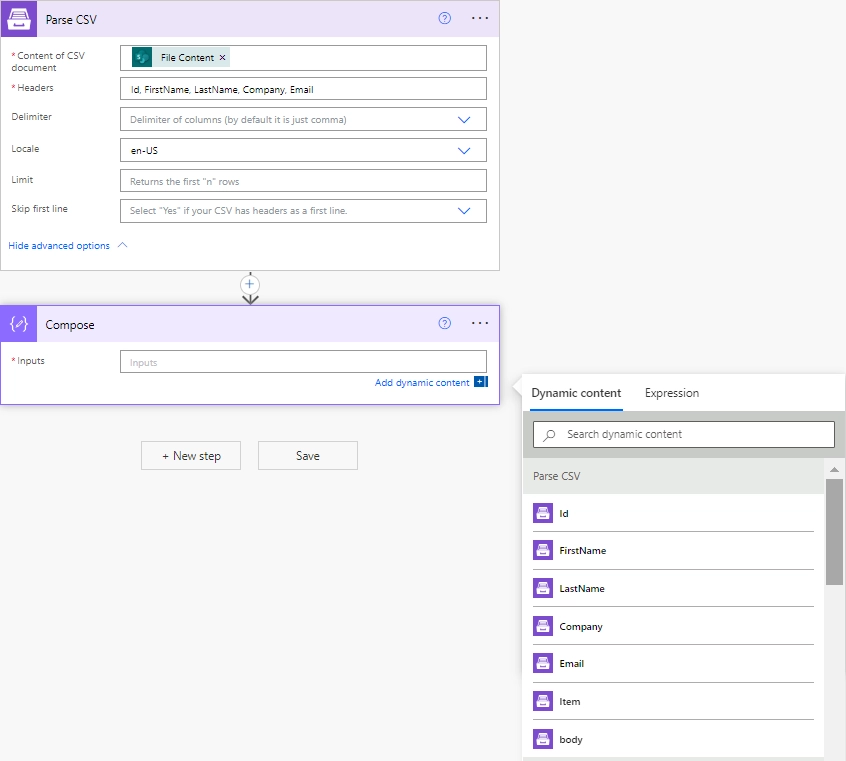
Content of CSV document |
The raw content of the source CSV file. You can extract file content from other connectors like:
|
It is content of the source file. |
Headers |
Comma separated list of columns. |
You need to specify the headers in the same order as in the CSV file. Ex.: Id, FirstName, LastName, Company, Email |
Delimiter |
Delimiter of columns. By default it’s a comma. |
You can select from the following default values: Comma, Semicolon, Tab or specify a custom value. |
Locale |
The locale that will be applied to the source document. |
Specify the locale to correctly parse currencies, dates, and other dependent values. Different countries use different separators for numbers, and the action handles them correctly. |
Limit |
Returns the first “n” rows |
You can limit the number of returned rows from the source document. |
Skip first Line |
Select ‘Yes’ if your CSV has headers as a first line |
If your CSV file has headers as a first line the select ‘Yes’. In that case the action will start collecting the values from the second line of the CSV file. If you select ‘No’, or the empty value then the action will start collecting values from the first line of the CSV file. |
Example
Create Archive
Create a compressed ZIP archive with Power Automate (Microsoft Flow). Optionally, you may apply password protection.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
File Content |
Raw content of the result archive. |
It is the Base64-encoded content of the result archive. |
Filename |
Full name of the result file. |
It is the name provided in the File Name input parameter plus the “.zip” extension. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
File Name |
Name of the result file. |
It is the name of the archive that will be produced by this action. |
Documents |
The array of Base64-encoded files that need to be added to the archive and their full names (with extensions). |
You may get the content of files with the “Get file content” action from the “SharePoint” connector or any other suitable connector. If the documents collection is specified as an array object, the JSON of the object may look as follows: [
{
"fileName": "file 1.txt",
"content": "RXhhbXBsZSBkYXRhCg=="
},
{
"fileName": "file 2.txt",
"content": "VGhlIHNlY29uZCBleGFtcGxlCg=="
}
]
|
Password |
The password used to protect the archive. Optional. |
A string of text without any specific limitations. |
Example
You can add individual files:
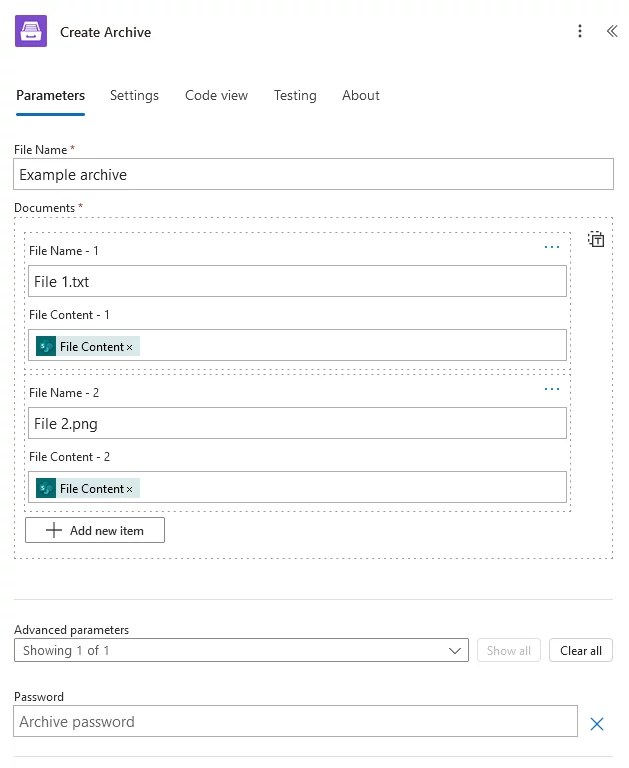
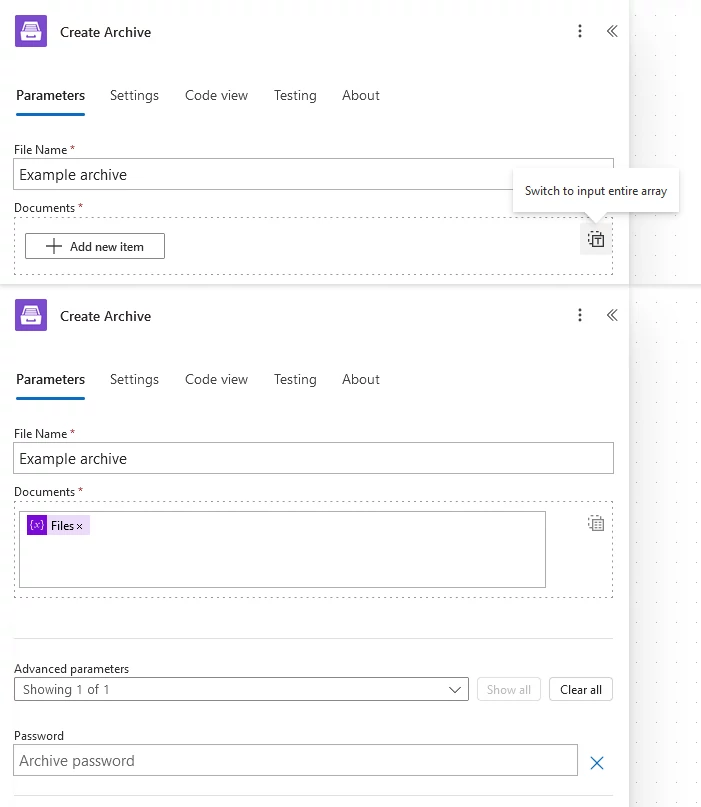
You can also input an array of files. Click an icon on the right to switch to the view where you can input an entire array and select the array from the dynamic content in Power Automate:
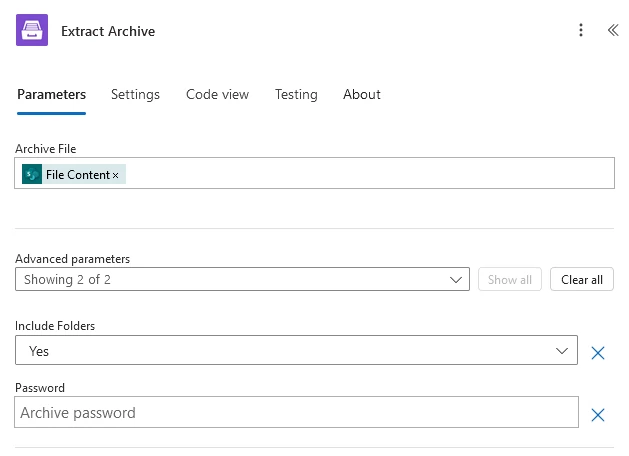
Extract Archive
Extract a compressed archive with Power Automate (Microsoft Flow). The following formats are supported: 7z, xz, bzip2, gzip, tar, zip, wim, apfs, ar, arj, cab, chm, cpio, cramfs, dmg, ext, fat, gpt, hfs, ihex, iso, lzh, lzma, mbr, msi, nsis, ntfs, qcow2, rar, rpm, squashfs, udf, uefi, vdi, vhd, vhdx, vmdk, xar, z.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result files File Content |
The array of raw content of extracted files. |
It is an array of Base64-encoded contents of files extracted from the archive. You can iterate through them and save them somewhere. |
Result files Filename |
The array of full names (with extensions) of extracted files. |
It is an array of strings. You can use them in the same loop where you iterate over Result files File Content. |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Archive File |
Raw content of the archive to be extracted. |
It is the Base64-encoded content of the input archive. |
Include Folders |
Specifies whether files from nested folders within the archive should also be extracted. |
No |
Password |
The password used to protect the archive. Optional. |
A string of text without any specific limitations. |
Example
Regular Expression Match
Searches an input string for all occurrences of a regular expression and returns all the matches with the help of Power Automate (Microsoft Flow).
Note
If you have an active Plumsail Documents subscription, this action is free, i.e., it doesn’t consume documents limit of the subscription. Please also check the licensing details.
We would recommend you to use Regex 101 tool to test your expressions. It supports the same syntax as actions. By default, Regex101 works with the PCRE2 syntax. You should change it to .NET (C#) in the “Flavor” section under “Save & Share”.
You can find more examples in this article.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Is Success |
True if the input string has at least one occurrences of a regular expression, otherwise false. |
true |
Matches |
The dynamic response based on a pattern that is used in this action. Contains all matches groups that included in the pattern (named or unnamed). |
Match0, TaskId, status |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
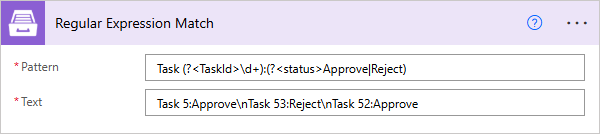
Pattern |
Regular expression pattern. This pattern can contain inline options to modify behavior of the regular expression. Such options have to be placed in the beginning of the expression inside brackets with question mark: |
|
Text |
String to search for matches. |
|
Example
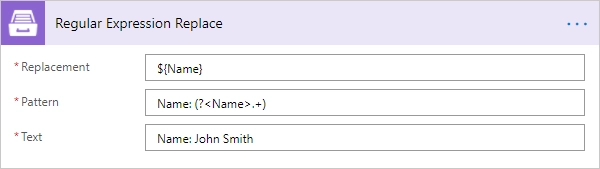
Regular Expression Replace
In a specified input string, replaces all strings that match a regular expression pattern with a specified replacement string.
Note
If you have an active Plumsail Documents subscription, this action is free, i.e., it doesn’t consume documents limit of the subscription. Please also check the licensing details.
We would recommend you to use Regex 101 tool to test your expressions. It supports the same syntax as actions. By default, Regex101 works with the PCRE2 syntax. You should change it to .NET (C#) in the “Flavor” section under “Save & Share”.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Result |
Result string with replaced substrings that match a regular expression pattern. |
|
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Pattern |
Regular expression pattern. This pattern can contain inline options to modify behavior of the regular expression. Such options have to be placed in the beginning of the expression inside brackets with question mark: |
|
Text |
String to search for matches. |
|
Replacement |
Replacement string or backreference. The name or number of a captured group should be put between braces in |
|
Example
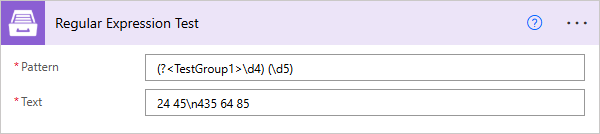
Regular Expression Test
Indicates whether the regular expression specified in the Regex constructor finds a match in a specified input string.
Note
If you have an active Plumsail Documents subscription, this action is free, i.e., it doesn’t consume documents limit of the subscription. Please also check the licensing details.
We would recommend you to use Regex 101 tool to test your expressions. It supports the same syntax as actions. By default, Regex101 works with the PCRE2 syntax. You should change it to .NET (C#) in the “Flavor” section under “Save & Share”.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
Is Success |
True if the input string has at least one occurrences of a regular expression, otherwise false. |
true |
Input Parameters
Parameter |
Description |
Example |
|---|---|---|
Pattern |
Regular expression pattern. This pattern can contain inline options to modify behavior of the regular expression. Such options have to be placed in the beginning of the expression inside brackets with question mark: |
|
Text |
String to search for matches. |
|
Example
Get Profile Info
Returns information about the account whose API Key is specified in the Plumsail Documents connector’s settings.
This action has no input parameters.
Output Parameters
Parameter |
Description |
Example |
|---|---|---|
body/name |
The account’s name. |
|
body/email |
The email address tied to the account. |
|
body/licenseStatus |
Either the word “Expired” or an integer value that corresponds to the account’s license type. Refer to the License Types section for the list of possible license type values. |
20 |
body/teamName |
The name of the team that the account is assigned to. |
Sales team |
body/licenseInfo/type |
An integer value that corresponds to the account’s license type. Refer to the License Types section for the list of possible license type values. |
20 |
body/licenseInfo/credits |
The number of documents currently available to this account. |
1000 |
body/licenseInfo/additionalCredits |
The number of additional documents currently available to this account. |
200 |
body/licenseInfo/expirationDate |
The expiration date of the license in ISO 8601 format. |
2025-10-20T23:59:59 |
body/shortUserId |
The account’s ID. It is required when making some API calls. |
abcdefgh |
License Types
The following table contains possible license type values.
License name |
License type value |
|---|---|
Documents Trial |
20 |
Documents Folder |
21 |
Documents Drawer |
22 |
Documents Cabinet |
23 |
Documents Custom |
29 |
Example