
Documents
Nov 07, 2024
How to split PDF using Make
Learn how to split PDF documents in Make and the Plumsail Documents connector. This guide covers three methods - extracting specific pages, dividing PDF into even chunks, and splitting by bookmarks.

Extracting data from PDF files is a common task when building scenarios in Make. Whether you are working with invoices, forms, contracts, or reports, the goal is often the same — extract text from PDF and turn it into structured data you can use.
But simply getting plain text from a PDF is not enough. You often need to extract specific values such as dates, names, reference numbers, or totals and use that structured data in Google Sheets or other systems. This is where the ability to extract data from PDF and automate PDF processing becomes essential.
In the Make Community, I came across multiple questions like these:
Sorry for the trouble, but there's something I can't figure out. I'm trying to convert PDF files into text. My idea is simple: take invoices in PDF format and load them into Google Sheets or Excel tables. That's it.
I want to extract the raw text from a PDF file, I can use the Google Drive module “download file��”. It gives me raw data, how can I convert it to text?
These real questions were the reason I wrote this article. It shows how to extract text from PDF using Plumsail Documents inside a Make scenario, apply regular expressions to extract data from PDF, and use that data in Google Sheets.
If you are looking for a clear and practical way to extract info from PDF and automate PDF processing in Make, this guide will walk you through the entire process.
Further in the article:
In this scenario, Make monitors a Gmail inbox for incoming messages. When a new email arrives with a PDF attachment, the file is sent to Plumsail Documents, which extracts the full text content from the PDF. I then use a regular expression to extract specific data points such as the invoice number, issue date, sender name, and total amount directly from the text.
The extracted data is added to Google Sheets in a structured format. This makes it easy to store, process, or connect the values with other systems.
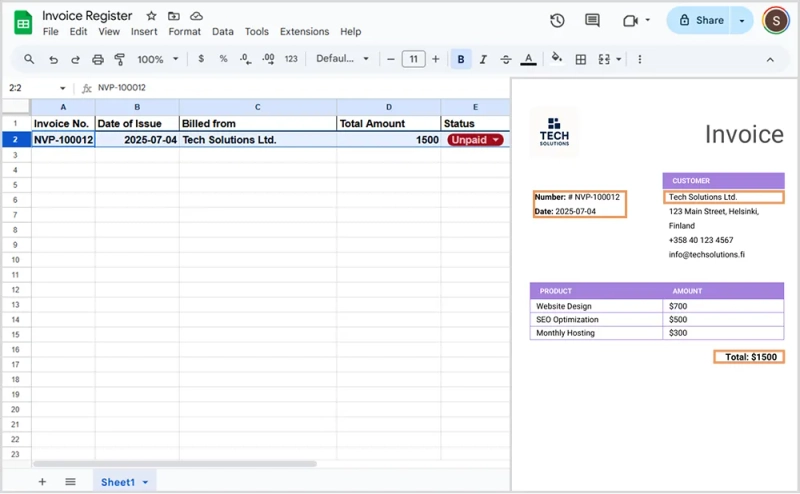
This is the original invoice document from which the data will be extracted:

With this setup, I can fully automate PDF processing. There is no need to open files or copy values manually. Everything runs in the background inside Make.
If you'e new to Make, there is a special offer: you can get 2 free months of the Make Pro plan by registering through our partner link. This offer is valid for new accounts only.
Let's start.
The scenario starts with Gmail → Watch emails, which monitors my inbox for new messages. Then I use List email attachments to find the files attached to those emails. For each PDF attachment, I run Plumsail Documents → Extract text from PDF to get the full plain text content.
Once I have the text, I apply Plumsail Documents → RegExp Match to extract specific fields: invoice number, date, client name, and total. Finally, I use Google Sheets → Add a row to write this data into a table — one row per invoice.
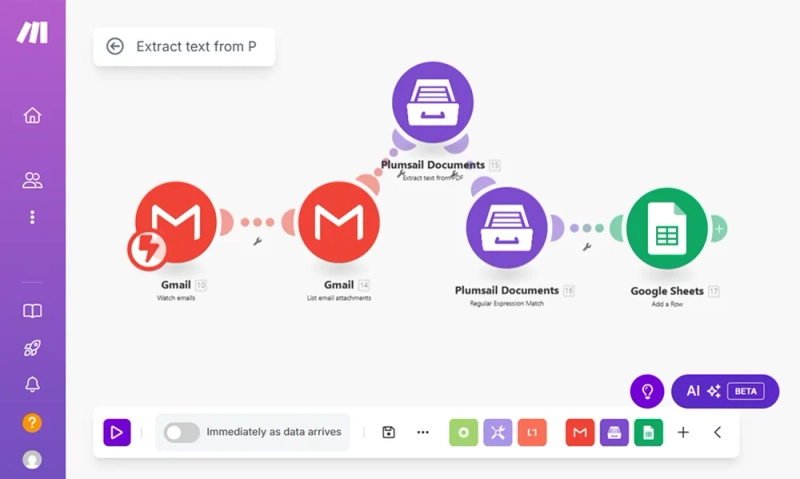
Now let's go through each step in more detail.
I started with the Gmail → Watch emails module. It monitors my inbox and triggers the scenario when a new message arrives.
Here is how I configured it:
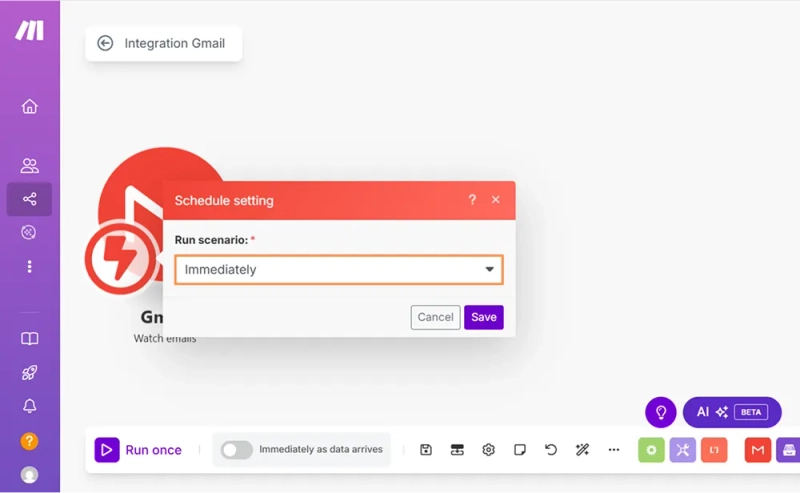
The setup for this Gmail module is complete. Next, I'll configure the module that works with email attachments.
After setting up email monitoring, I added the Gmail → List attachments module. It takes the message ID from the previous step and returns all attached files.
Here is how I configured it:
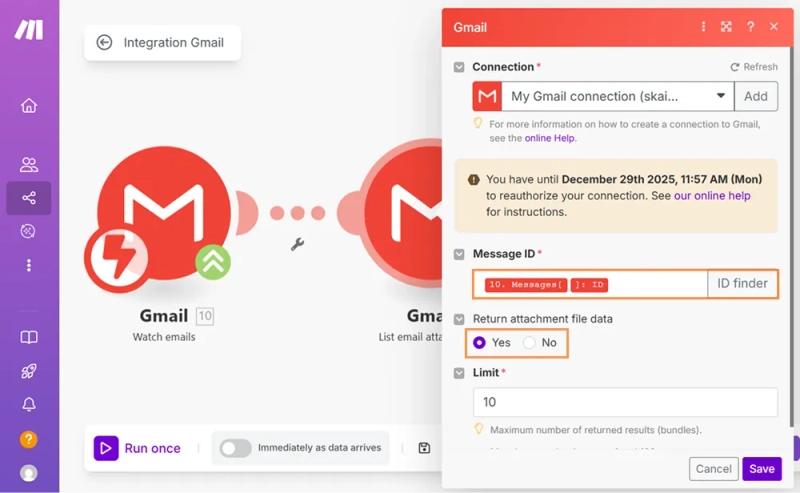
This module gives me direct access to the files in each email. In the next step, I'll pass the PDF attachments to the text extraction module.
Now that I have access to the attachments, I added the Plumsail Documents → Extract text from PDF module. It extracts info from PDF and returns its content as plain text or HTML, depending on the output format you choose. If you're using Plumsail Documents for the first time, you'll automatically get a 30-day free trial with full access to all features.
Here is how I configured it:
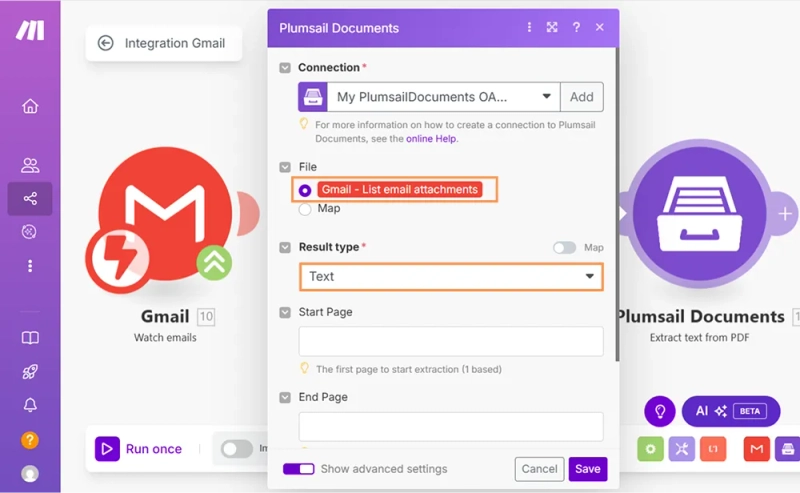
This module will return raw text that I can then process further with regular expressions.
This module helps extract structured data from the plain text returned by the Extract text from PDF step.
I selected my existing Plumsail Documents connection.
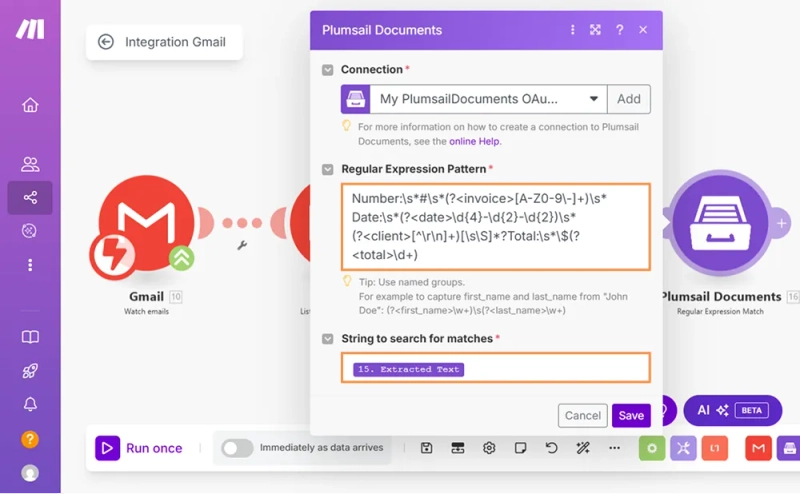
In the Regular Expression Pattern field, I used this expression:
Number:\s*#\s*(?<invoice>[A-Z0-9\-]+)\s*
Date:\s*(?<date>\d{4}-\d{2}-\d{2})\s*
(?<client>[^\r\n]+)[\s\S]*?Total:\s*\$\s*(?<total>\d+)
It captures the invoice number, date, client name, and total amount using named groups. Specifically:
(?<invoice>[A-Z0-9\-]+) — captures the invoice number like NVP-100012.
(?<invoice>...) — named group called invoice[A-Z0-9\-]+ — matches one or more uppercase letters (A-Z), digits (0-9), or hyphens (-)
(?<date>\d{4}-\d{2}-\d{2}) — captures the invoice date in YYYY-MM-DD format, like 2025-07-04.
(?<date>...) — named group called date\d{4} — four digits (year)- — hyphen\d{2} — two digits (month), then two digits (day)
(?<client>[^\r\n]+) — captures the client name, for example Tech Solutions Ltd.
(?<client>...) — named group called client[^\r\n]+ — matches one or more characters that are not a line break (\r or \n)
(?<total>\d+) — captures the total amount, such as 1500.
(?<total>...) — named group called total\d+ — matches one or more digits
This makes it easier to map the extracted values directly to columns in Google Sheets or any other destination in your workflow.
If you're not sure how to write a regular expression or want to test your pattern, these resources can help:
In the String to search for matches field, I mapped the Extracted Text output from the previous module.
This module gives me only the key data I need, so I can push it directly to a Google Sheet without cleaning or parsing manually.
That completes the configuration of the Plumsail Documents → RegExp Match module.
Note Regular expressions depend on the exact structure of the text. If the PDF format is different — for example, line breaks are placed differently, or labels like TOTAL or BILL TO are written in another way, the pattern might fail and return no results.
To solve this, you can:
The final module in the scenario is Google Sheets → Add a Row. I used it to record invoice data into a spreadsheet automatically.
Here's how I configured it:
/Invoice RegisterThen I mapped the extracted values from the RegEx module into the table columns:
invoicedateclienttotal"Unpaid" by default
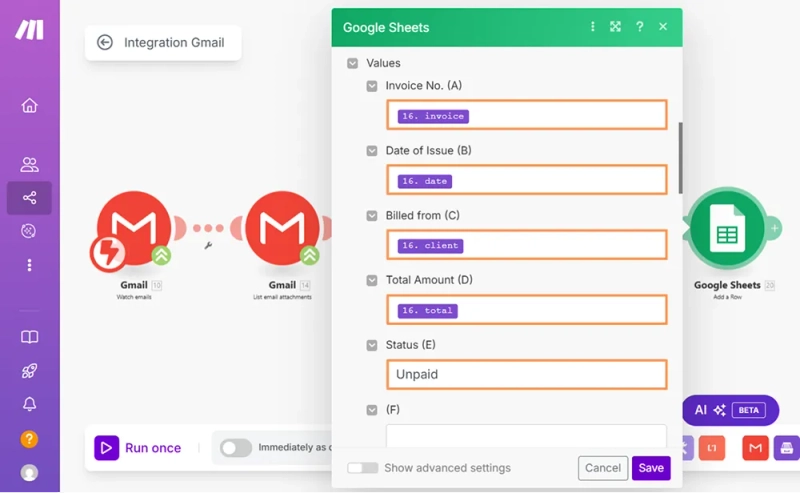
This completes the setup of the Google Sheets step. When the full scenario runs, each matching invoice is recorded in a new row automatically.
This approach can be used in many other scenarios, not just for collecting invoice data.
Once the text is extracted, it becomes much easier to work with documents across your entire workflow.
Register an account for a 30-day free trial. Start extracting text from PDFs and explore other Plumsail Documents actions in Make.
Here is a Make Pro promo link for new users that gives you 2 months of Make Pro for free.
Need help? Book a free intro call with the Plumsail team, and we'll assist with your automation needs.
Learn how to split PDF documents in Make and the Plumsail Documents connector. This guide covers three methods - extracting specific pages, dividing PDF into even chunks, and splitting by bookmarks.
Learn how to merge Airtable attachments into a single PDF easily with Make, whether combining PDFs or converting images into a consolidated PDF file.
Plumsail Documents is now available on the Make platform to bring even more flexibility to your document generation.



